In my eight years working in technical support and customer service within the telecommunications sector, I’ve witnessed firsthand how network infrastructure decisions can make or break IoT deployments. At InterLIR, where we specialize in solving network availability problems through our IPv4 address marketplace, we understand the critical importance of addressing schemes and secure connectivity. Amazon Web Services’ recent announcement regarding enhanced IoT service capabilities represents a significant milestone that addresses two fundamental challenges our clients frequently encounter: security isolation and future-proof addressing strategies.
AWS has announced substantial enhancements to its Internet of Things service suite, expanding support for Virtual Private Cloud (VPC) endpoints and IPv6 connectivity across AWS IoT Core, AWS IoT Device Management, and AWS IoT Device Defender services. These improvements, announced in November 2025, mark a strategic evolution in enterprise-grade IoT infrastructure, addressing the growing demands for enhanced security, private networking capabilities, and scalable addressing schemes that we regularly discuss with our customers at InterLIR.
Understanding the Strategic Importance of AWS IoT Enhancements
The latest improvements to AWS IoT services represent more than incremental updates-they constitute a fundamental shift in how organizations can architect their IoT infrastructure. From my perspective working with clients who manage complex network environments, these enhancements address two critical pain points that have historically limited enterprise IoT adoption: security exposure through public internet connectivity and the looming exhaustion of IPv4 address space.
At InterLIR, founded in 2020 in Berlin under the leadership of CEO Alexander Timokhin, we’ve built our business around understanding network availability challenges. Our work in the IPv4 marketplace has given us unique insights into how addressing limitations impact infrastructure planning. The dual enhancement of VPC endpoint expansion and IPv6 support directly addresses concerns we hear daily from enterprise clients evaluating IoT deployments.
VPC Endpoint Expansion Through AWS PrivateLink
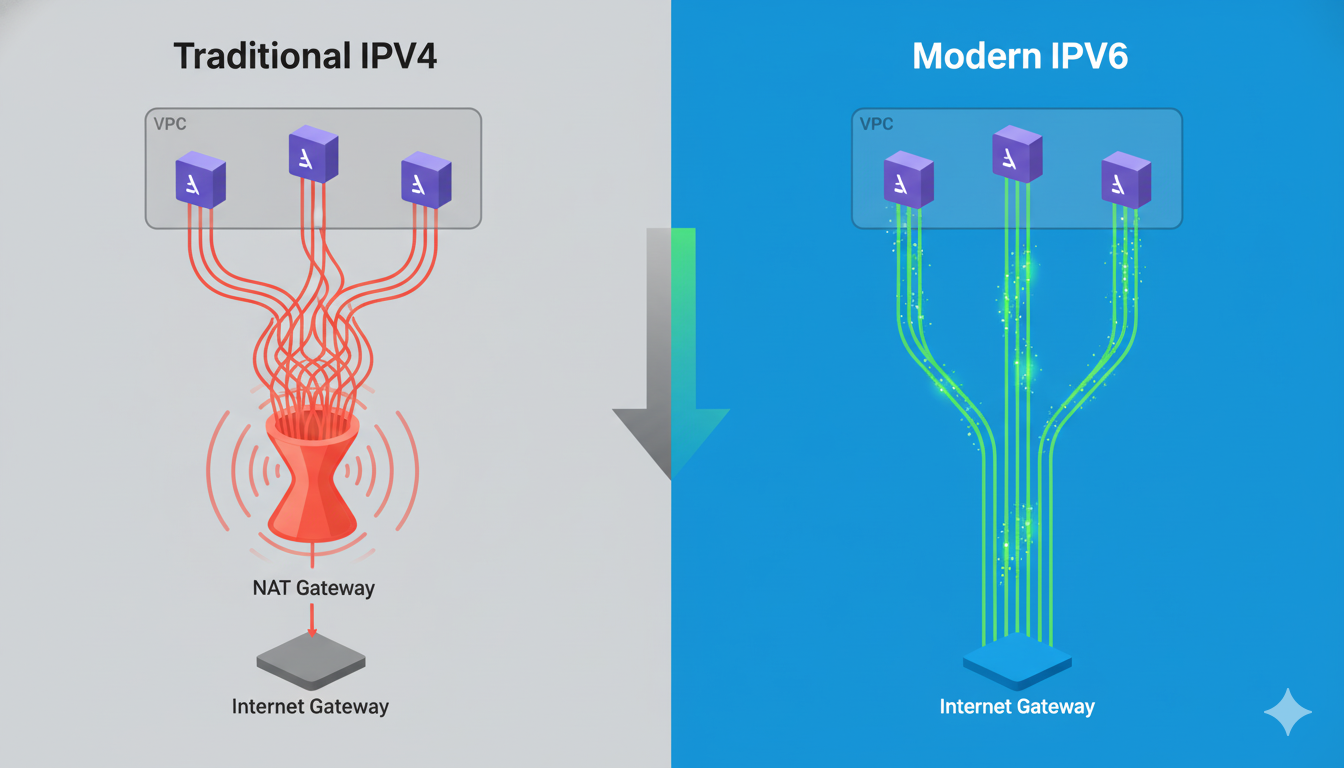
AWS PrivateLink technology now enables VPC endpoints for comprehensive AWS IoT service operations, creating what amounts to a private highway for IoT communications. This expansion covers three critical operational areas that previously required public internet exposure:
🔒 Data plane operations – Secure data transfer between IoT devices and AWS services without internet exposure
🛠️ Management APIs – Administrative functions for IoT service configuration and management through private channels
🔑 Credential provider – Authentication services for device identity and access management within private networks
The significance of this expansion cannot be overstated. Organizations can now implement complete IoT workloads within their virtual private clouds without data ever traversing the public internet. This substantially reduces the attack surface and potential exposure to external threats-a concern that keeps many CISOs awake at night when evaluating cloud-based IoT solutions.
In my experience supporting telecommunications clients, the ability to maintain private connectivity throughout the entire IoT stack addresses one of the most common objections to cloud adoption. Previously, even organizations with robust VPC architectures had to accept some level of public internet exposure for certain IoT operations. That compromise is no longer necessary.
IPv6 Support for Future-Proof Connectivity
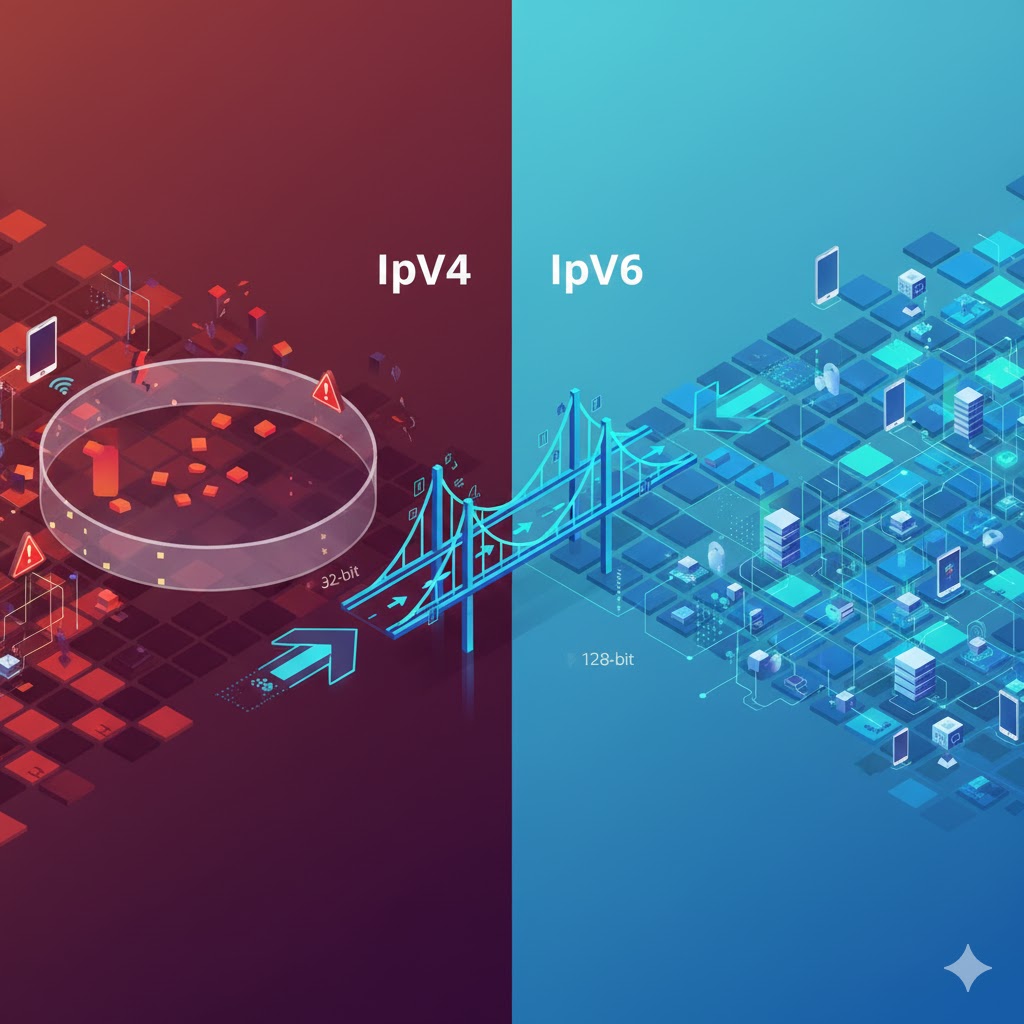
The addition of IPv6 support addresses a challenge that InterLIR deals with daily: the finite nature of IPv4 addresses. While our IPv4 marketplace helps organizations acquire the addresses they need today, we always counsel clients to plan for IPv6 adoption as part of their long-term strategy. AWS’s implementation of dual-stack functionality provides exactly the kind of transition flexibility that makes practical sense:
🌐 IPv6 connectivity – Support for the vastly expanded address space needed for billions of connected devices
🔄 Dual-stack compatibility – Simultaneous support for both IPv6 and IPv4 connections during transition periods
📋 Regulatory compliance – Ability to meet regional requirements mandating IPv6 implementation, particularly in Asia and Europe
📈 Scalability planning – Elimination of addressing constraints for massive IoT deployments
This dual-protocol approach is particularly valuable for organizations managing a transition strategy. Working with Alexei Krylov, our Head of Sales, and Evgeny Sevastyanov, our Head of Customer Support, I’ve seen how challenging it can be for organizations to balance immediate IPv4 needs with long-term IPv6 planning. AWS’s approach allows organizations to support legacy IPv4 devices while implementing new deployments with IPv6-native connectivity-a pragmatic solution to a complex transition challenge.

AWS dual-stack IPv4 and IPv6 network infrastructure with global connectivity
Technical Implementation and Global Availability
These enhancements represent fully operational capabilities available across AWS’s global infrastructure, not theoretical improvements or limited beta features. From a practical implementation standpoint, developers and infrastructure teams can leverage these enhanced connectivity options through multiple deployment methods:
⚙️ AWS Management Console – Graphical interface for configuration, ideal for initial setup and testing
💻 AWS CLI – Command-line implementation for automation and scripting
📑 AWS CloudFormation – Infrastructure-as-code deployment for consistent, repeatable implementations
🔧 AWS SDKs – Programmatic integration for custom applications and workflows
The general availability spans all AWS regions where IoT Core, IoT Device Management, and IoT Device Defender are offered, ensuring global consistency for multi-region deployments. This worldwide availability is crucial for multinational organizations that need consistent security and connectivity architectures across geographic boundaries.
Implementation Considerations and Best Practices
Based on my experience supporting complex network implementations, organizations planning to leverage these new capabilities should carefully consider several implementation factors. I’ve developed this framework through years of helping clients navigate similar infrastructure transitions:
| Consideration | Impact | Recommendation |
|---|---|---|
| Security architecture | Enhanced isolation potential | Review existing security groups and NACLs for alignment with VPC endpoint implementation; update security documentation |
| Network design | Traffic flow changes | Update network diagrams and routing tables to account for private endpoint paths; test failover scenarios |
| Cost structure | PrivateLink pricing implications | Analyze data transfer volumes to estimate PrivateLink costs versus public endpoint usage; factor in security value |
| Device addressing | IPv6 implementation complexity | Plan addressing scheme that accommodates both IPv4 and IPv6 devices during transition; document allocation strategy |
| Monitoring and logging | New traffic patterns | Update monitoring tools to track VPC endpoint usage; ensure logging captures private connectivity metrics |
Security Posture Enhancement and Zero-Trust Architecture
The expansion of VPC endpoints addresses one of the most significant concerns in enterprise IoT deployments: network exposure. In my role at InterLIR, where we focus on solving network availability problems, I’ve observed that security concerns often rank alongside addressing limitations as primary barriers to IoT adoption in regulated industries.
By enabling private connectivity for the entire IoT service stack, AWS has eliminated a common objection to cloud-based IoT implementations in high-security environments such as healthcare, financial services, and critical infrastructure. The ability to contain all IoT communication within private network boundaries aligns perfectly with zero-trust security principles, where no network traffic is trusted by default, and all connections require explicit verification regardless of their origin.
Practical Security Benefits
The security advantages of VPC endpoint implementation extend beyond theoretical improvements. From a practical standpoint, organizations gain several concrete benefits:
🛡️ Reduced attack surface – Elimination of public internet exposure removes entire categories of potential attack vectors
🔍 Simplified compliance – Private connectivity makes it easier to demonstrate compliance with data protection regulations
📊 Enhanced visibility – VPC Flow Logs provide detailed visibility into IoT traffic patterns within private networks
🔐 Granular access control – Security groups and NACLs provide fine-grained control over IoT service access
🚫 Data exfiltration prevention – Private connectivity makes it significantly harder for compromised devices to communicate with external command-and-control servers
IPv6 and the Future of IoT Connectivity
At InterLIR, our work in the IPv4 marketplace gives us a unique perspective on addressing challenges. While we help organizations acquire the IPv4 addresses they need today, we’re also advocates for IPv6 adoption as a long-term strategy. AWS’s implementation of dual-stack support addresses both immediate and long-term connectivity challenges in ways that align with our recommendations to clients:
Addressing the Scale Challenge
The theoretical limit of 4.3 billion IPv4 addresses is fundamentally insufficient for global IoT deployment scenarios. Consider these scale implications:
📈 Device proliferation – Industry analysts project 75 billion connected devices by 2030, far exceeding IPv4 capacity
🏭 Industrial IoT density – A single smart factory might require tens of thousands of unique addresses
🏙️ Smart city infrastructure – Municipal IoT deployments can easily require millions of addresses for sensors, cameras, and connected infrastructure
🚗 Connected vehicles – Automotive IoT alone could consume billions of addresses as vehicles become increasingly connected
IPv6’s 340 undecillion addresses (that’s 340 followed by 36 zeros) effectively eliminates addressing as a constraint on IoT deployment scale. This isn’t just theoretical-it’s a practical necessity for the IoT future we’re building.
Regional Compliance and Global Deployment
Many regions, particularly in Asia and Europe, have regulations encouraging or requiring IPv6 support. For multinational organizations, the ability to support both addressing schemes simultaneously eliminates potential barriers to global deployment standardization. This is particularly relevant for our clients at InterLIR who operate across multiple jurisdictions and need to balance regional requirements with operational consistency.
Global network map showing IPv6 deployment across multiple regional data centers
Industry-Specific Use Cases and Business Impact
The practical implications of these enhancements extend across multiple industries. Based on my experience supporting telecommunications clients and understanding network infrastructure requirements, I can identify several high-impact use cases:
Healthcare IoT Security
Healthcare organizations handling protected health information (PHI) through connected medical devices face stringent regulatory requirements. The combination of VPC endpoints and dual-stack addressing provides a compelling solution:
🏥 Patient monitoring – Data from bedside monitors, wearables, and implantable devices can flow through private channels
💊 Medication management – Smart dispensing systems can communicate securely without internet exposure
🔬 Laboratory equipment – Connected diagnostic devices can transmit results through private networks
📱 Telehealth infrastructure – Remote patient monitoring systems can maintain HIPAA compliance while leveraging cloud analytics
By using VPC endpoints, patient data transmitted from monitoring equipment never traverses the public internet, helping maintain HIPAA compliance while still leveraging cloud-based analytics and management capabilities. This addresses a critical concern that has historically limited cloud adoption in healthcare IoT.
Industrial IoT at Scale
Manufacturing and industrial organizations deploying sensors across factory floors benefit from both enhanced security and expanded addressing capabilities. A typical smart factory implementation might include:
🏭 Production line sensors – Thousands of sensors monitoring equipment performance, environmental conditions, and product quality
🤖 Robotics and automation – Connected industrial robots requiring secure, reliable communication
📊 Predictive maintenance systems – Vibration sensors, thermal cameras, and other diagnostic equipment
🔋 Energy management – Smart meters and power monitoring systems across facilities
The combination of private connectivity and IPv6 addressing allows for secure, scalable deployments that can grow to hundreds of thousands of sensors within a private network architecture. This scalability without security compromise is exactly what industrial IoT deployments require.
Smart Infrastructure and Critical Systems
Municipal smart city initiatives and critical infrastructure projects often face both security scrutiny and large-scale deployment requirements. These projects typically involve:
🚦 Traffic management – Connected traffic lights, sensors, and cameras requiring secure communication
💡 Smart lighting – Streetlight networks with environmental sensors and emergency response capabilities
💧 Utility monitoring – Water, gas, and electric infrastructure with thousands of monitoring points
🚨 Public safety systems – Emergency response infrastructure requiring the highest security standards
The enhanced AWS IoT services enable these projects to implement private, secure communication channels while planning for massive device deployment through IPv6 addressing. This combination is essential for critical infrastructure where security cannot be compromised, but scale cannot be limited.
Cost-Benefit Analysis and Financial Considerations
While implementing VPC endpoints through PrivateLink does introduce additional costs compared to using public endpoints, organizations should consider the complete financial equation. In my experience advising clients on network infrastructure investments, the security and operational benefits often justify the additional expense:
Direct and Indirect Cost Factors
| Cost Category | Consideration | Financial Impact |
|---|---|---|
| PrivateLink charges | Hourly endpoint charges plus data processing | Predictable, calculable costs based on endpoint count and data volume |
| Security incident prevention | Reduced breach risk and associated costs | Potential savings of millions in breach remediation and reputation damage |
| Compliance simplification | Reduced audit complexity and documentation burden | Lower compliance costs and faster certification processes |
| Operational efficiency | Consistent security architecture across services | Reduced management overhead and training requirements |
| IPv6 transition costs | Addressing scheme planning and implementation | One-time investment versus ongoing IPv4 acquisition costs |
At InterLIR, where we help organizations acquire IPv4 addresses, we’re transparent about the long-term cost implications. IPv4 addresses are a finite resource with increasing costs. Organizations implementing new IoT deployments should seriously consider IPv6-native implementations to avoid ongoing IPv4 acquisition expenses as their deployments scale.
Implementation Roadmap and Migration Strategy
Based on my experience supporting complex infrastructure transitions, I recommend a phased implementation approach that balances risk management with capability adoption:
1️⃣ Assessment phase (2-4 weeks) – Evaluate existing IoT architecture, identify security gaps addressable through VPC endpoints, and document current addressing schemes. Engage stakeholders across security, networking, and application teams to understand requirements and constraints.
2️⃣ Design phase (3-6 weeks) – Develop comprehensive VPC endpoint implementation plan, design IPv6 addressing scheme, and create detailed network architecture diagrams. Include cost modeling and security architecture documentation.
3️⃣ Test deployment (4-8 weeks) – Implement in non-production environment to validate architecture, test failover scenarios, and verify monitoring and logging capabilities. Include performance benchmarking and security testing.
4️⃣ Pilot production migration (6-12 weeks) – Select low-risk production workloads for initial migration, establish success metrics, and refine procedures based on real-world experience.
5️⃣ Full production migration (3-6 months) – Gradually transition remaining production workloads to enhanced connectivity model, maintaining rollback capabilities and monitoring closely for issues.
6️⃣ Monitoring and optimization (ongoing) – Evaluate performance, security, and cost metrics to refine implementation. Establish continuous improvement processes for security posture and operational efficiency.
Critical Success Factors
Throughout this implementation journey, several factors will determine success:
👥 Cross-functional collaboration – Security, networking, and application teams must work together closely
📚 Documentation discipline – Maintain detailed documentation of architecture decisions, addressing schemes, and security controls
🧪 Thorough testing – Test not just happy paths but failure scenarios and edge cases
📊 Metrics-driven decisions – Establish clear success metrics and monitor them consistently
🔄 Iterative improvement – Treat implementation as an ongoing process, not a one-time project
Expert Perspectives and Industry Implications
Industry experts view these enhancements as significant advancements in enterprise IoT infrastructure. Security specialists particularly note that the expanded VPC endpoint support addresses a critical gap in many IoT security architectures, where device data was previously forced to traverse public networks despite otherwise robust security controls.
Network architects highlight that the dual IPv4/IPv6 support represents a pragmatic approach to addressing transition, acknowledging that most organizations will need to support both protocols for the foreseeable future rather than making an abrupt switch. This aligns perfectly with the guidance we provide at InterLIR-plan for IPv6, but maintain IPv4 capabilities during the transition period.
From my perspective working in telecommunications and network infrastructure, these enhancements represent AWS listening to enterprise customers and addressing real-world concerns. The combination of enhanced security through private connectivity and future-proof addressing through IPv6 support creates a compelling foundation for enterprise IoT deployments that need to scale securely over the coming decade.
AWS’s expanded support for VPC endpoints and IPv6 connectivity across its IoT service suite represents a significant advancement for enterprise IoT deployments that addresses fundamental security and scalability challenges. These enhancements provide organizations with the tools to implement fully private IoT communication flows while simultaneously preparing for the inevitable transition to IPv6 addressing-two capabilities that are increasingly essential as IoT evolves from experimental technology to mission-critical infrastructure.
In my eight years supporting telecommunications clients and now working at InterLIR, where we focus on solving network availability problems, I’ve seen how addressing limitations and security concerns can constrain IoT ambitions. AWS’s latest enhancements directly address both challenges, potentially accelerating adoption in security-sensitive industries and enabling large-scale deployment scenarios that were previously impractical or prohibitively expensive.
For organizations invested in IoT as strategic infrastructure, these capabilities offer both immediate security benefits and long-term architectural flexibility. The ability to implement private connectivity throughout the IoT stack reduces attack surfaces and simplifies compliance, while dual-stack addressing support provides a pragmatic path forward as the industry transitions from IPv4 to IPv6.
Organizations should evaluate these new capabilities against their current IoT security architecture and future connectivity requirements to determine implementation priorities. Consider starting with a pilot project that demonstrates the security and operational benefits, then develop a phased migration plan that balances risk management with capability adoption. The investment in proper planning and implementation will pay dividends in enhanced security, operational efficiency, and long-term scalability.
As we continue to support clients at InterLIR in navigating network infrastructure challenges, we’ll be recommending that organizations seriously consider these AWS IoT enhancements as part of their overall connectivity strategy. The combination of private connectivity and future-proof addressing represents exactly the kind of forward-thinking infrastructure investment that positions organizations for success in an increasingly connected world.