🎯 Critical Infrastructure Concentration: A single six-hour technical failure at Cloudflare disrupted 20% of global internet traffic on November 18, 2025, affecting everything from AI chatbots to McDonald’s ordering kiosks-exposing dangerous dependency on a handful of infrastructure providers
💰 Massive Economic Impact: The outage cost between $5-15 billion per hour in aggregate losses across all affected businesses, with individual enterprises losing $300,000 to $1 million per hour depending on size
🚀 Strategic Action Required: Business leaders must immediately audit their infrastructure dependencies, implement multi-vendor redundancy strategies, and prepare “digital backup generators” for when-not if-the next major outage occurs
⚠️ Stock Market Lesson: Despite the catastrophic operational failure, Cloudflare’s stock declined only 2.8% by close, demonstrating that investors view infrastructure resilience as manageable risk when companies respond with transparency and concrete prevention measures
Let me start with a simple scenario that probably happened in your organization on November 18, 2025. Your marketing team couldn’t access their design tools in Canva. Your customer service platform went dark. Your developers couldn’t reach ChatGPT or Claude to assist with coding. Your employees couldn’t book time off because the HR system was down. And if you operate retail locations, your self-service kiosks might have displayed error pages instead of taking orders.
All of these failures-across completely different companies and platforms-had a single root cause: Cloudflare, the invisible infrastructure company that routes approximately 20% of all internet traffic, experienced a catastrophic technical failure that lasted nearly six hours. Think of Cloudflare as the electrical grid for the modern internet. When the grid goes down, it doesn’t matter how well-designed your building is or how much you’ve invested in your operations-the lights simply won’t turn on.
In simple terms, cloud infrastructure providers like Cloudflare are the digital equivalent of utilities-invisible until they fail, but absolutely critical to business operations. They determine whether your customers can reach your website, whether your applications function properly, and whether your digital services remain accessible during crucial business hours. When they go down, your business goes down with them, regardless of how much you’ve invested in your own technology.
What makes this particular incident a watershed moment is not just its scale-though affecting hundreds of millions of users and causing billions in losses certainly qualifies-but what it reveals about the hidden architecture risks in modern business operations. We’ve consolidated so much of our digital infrastructure around a handful of providers that their failures now cascade across entire sectors of the economy simultaneously. Understanding this concentration risk and preparing for it is no longer optional-it’s a fundamental business continuity requirement.
In this guide, I’ll break down what happened on November 18, 2025, translate the technical complexity into business language, explain why this matters for your strategic planning, and provide a clear roadmap for protecting your organization from similar disruptions in the future. Let’s start by understanding how we arrived at this precarious situation.
To understand today’s infrastructure vulnerability, I need to take you back to the early days of the commercial internet in the 1990s. Imagine the internet as a small town where every business ran its own servers, managed its own security, and handled its own traffic routing. This approach worked fine when there were thousands of websites, but it required significant technical expertise and capital investment that most businesses couldn’t sustain.
As the internet exploded in scale-from thousands of websites to billions-a natural consolidation occurred. Companies like Cloudflare, Amazon Web Services, and Microsoft Azure emerged as the “electrical utilities” of the digital age. They offered to handle all the complex infrastructure work-security, speed optimization, traffic routing, DDoS protection-so businesses could focus on their core competencies rather than managing servers.
This shift was enormously beneficial. A small e-commerce startup could access the same enterprise-grade infrastructure as Fortune 500 companies for a fraction of the cost. Websites loaded faster. Security improved dramatically. The technical barriers to launching a digital business dropped considerably. Think of it like moving from every building having its own generator to everyone connecting to a reliable power grid-it was more efficient, more cost-effective, and generally more reliable.
However, this consolidation created a new category of risk that we’re only now fully appreciating. When everyone connects to the same grid, a failure in that grid affects everyone simultaneously. Twenty years ago, as infrastructure expert Mike Chapple notes, individual service outages were common-you might go a week with at least one IT service down. But each outage affected only that one company. Today, we’ve achieved remarkable aggregate reliability through consolidation, but we’ve created a new risk: when one of these infrastructure giants stumbles, 20% of the internet goes down at the same time.
The numbers tell the story of this concentration. Cloudflare alone handles 81 million HTTP requests per second under normal conditions. Approximately 35% of Fortune 500 companies depend on their services. About 32% of the 10,000 most-visited websites globally utilize their infrastructure. We’ve essentially put a substantial portion of the global digital economy on a single platform-which is wonderful for efficiency but terrifying for resilience.
Let me translate the technical failure into a business analogy that captures what went wrong. Imagine you run a global logistics company with 330 distribution centers worldwide. Every five minutes, your central headquarters sends updated shipping instructions to all centers. These instructions are normally a manageable size-about 60 pages of directions.
On the morning of November 18, a well-intentioned change to your database security settings inadvertently caused the system to pull shipping data from two sources instead of one. Suddenly, those instruction files doubled in size to over 200 pages-exceeding what your distribution centers were designed to handle. The system at each center tried to load these oversized instructions, exceeded its memory capacity, and crashed completely. No orders could be processed. No shipments could go out. The entire operation ground to a halt globally.
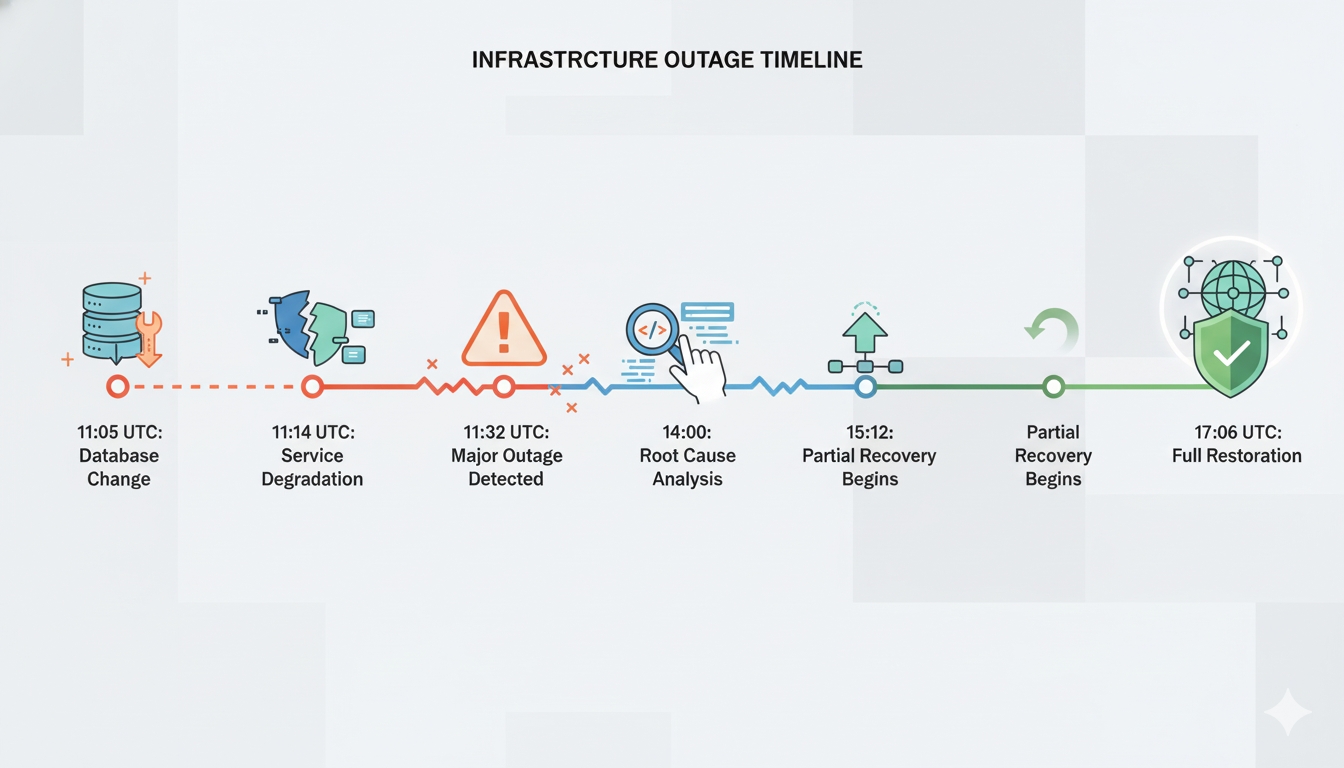
This is essentially what happened to Cloudflare. At 11:05 UTC, they made a routine database permissions change intended to improve security-the equivalent of upgrading your locks. This change triggered an unexpected consequence: a configuration file used by their Bot Management system began pulling duplicate data. The file size exploded from about 60 features to over 200 features. This oversized file was automatically distributed to all 330+ data centers within seconds via their rapid deployment system.
Here’s where the efficiency gains of modern infrastructure became a liability. Cloudflare’s deployment system can propagate changes globally in approximately seconds-an impressive engineering achievement that enables rapid security responses. But this same speed means errors also propagate instantly across all data centers before human operators can intervene. By the time anyone noticed the problem at 11:31 UTC-just 11 minutes after the first errors appeared-the defective configuration had already been distributed worldwide multiple times.
Adding to the diagnostic complexity, the failure pattern was intermittent. Services would work for five minutes, then fail for five minutes, then work again. This alternating pattern mimicked the characteristics of a cyberattack, leading the incident response team to initially investigate the wrong cause. It took until 14:24 UTC-more than three hours after the outage began-to identify the root cause and stop the automated system from generating oversized configuration files.
The scope of disruption extended far beyond what you might expect from a “technical” problem. Major platforms like X (Twitter), ChatGPT, Spotify, Discord, Zoom, and Shopify all went offline simultaneously. But the really striking impacts were in physical businesses: McDonald’s restaurants couldn’t take orders through their kiosks. Daycares couldn’t check children in or out electronically. Transit systems lost their real-time information displays. Corporate employees couldn’t access HR systems to request time off.
Even the monitoring systems failed. DownDetector-the website people use to check if other sites are down-itself went offline because it also relied on Cloudflare. This created a surreal situation where users had no reliable way to confirm whether their problems were isolated or part of a broader outage, contributing to confusion and anxiety across social media platforms.
When I discuss this incident with business leaders, the first question is always: “How much did this actually cost?” The answer reveals why infrastructure resilience must be a board-level concern, not just an IT issue.
Research on downtime costs shows that 93% of large enterprises experience downtime costs exceeding $300,000 per hour, while 48% report costs exceeding $1 million per hour. But these figures reflect individual company outages. When thousands of companies go offline simultaneously, the economic impact doesn’t add up-it multiplies.
Analysts estimate the aggregate economic damage at $5 to $15 billion per hour across all affected businesses. Over the six-hour duration, this translates to potential total losses in the hundreds of millions to several billion dollars. Let me break down where these costs accumulate:
💸 Direct Revenue Loss: E-commerce platforms couldn’t process transactions during peak shopping hours across multiple global time zones-every minute offline represents lost sales that will never be recovered
📉 Marketing Waste: Companies running active advertising campaigns continued paying for clicks and impressions that led to error pages instead of functioning websites-burning marketing budgets with zero return
🔥 Brand Damage: Studies show 88% of users are less likely to return to a website after a poor experience, even when they intellectually understand the cause was a third-party failure beyond the company’s control
⚖️ Contractual Penalties: Service-level agreements (SLAs) with customers triggered penalty clauses and mandated credits for missed uptime guarantees
👥 Productivity Collapse: Hundreds of millions of knowledge workers globally lost access to essential tools, with many simply unable to perform their jobs for the duration
📞 Support Cost Explosion: Customer service teams were overwhelmed with inquiries from users who didn’t realize the problem was widespread, diverting resources from normal operations
To make this concrete, consider the impact on foreign exchange and CFD brokers. These platforms facilitate approximately $1.58 billion in trading volume every three hours under normal conditions. During the Cloudflare outage, multiple brokers including Monaxa, Skilling, Xtrade, and FXPro experienced complete operational paralysis. Traders couldn’t access their positions, couldn’t execute trades, and couldn’t respond to market movements. The entire trading volume for that three-hour window-roughly equivalent to 1% of their typical monthly volume-simply evaporated.
Similarly, cryptocurrency exchanges reported significant declines in trading volumes during the peak outage period. NFT market activity contracted nearly to zero. Some blockchain Layer 2 networks that relied on Cloudflare for API connectivity became completely inaccessible, exposing the irony that “decentralized” applications often depend on centralized infrastructure.
Here’s the uncomfortable truth that keeps me up at night as an advisor: customers don’t care whose fault the outage was-they only care that your service didn’t work when they needed it. When your website displays a Cloudflare error page instead of loading properly, your brand takes the reputational hit, even though the technical failure occurred in infrastructure you don’t control.
This is why viewing infrastructure providers as “someone else’s problem” is a strategic mistake. Their reliability directly impacts your customer experience, your revenue, and your competitive positioning. Treating this as purely a technical concern rather than a business risk is like assuming your building’s foundation isn’t your concern because you’re not a structural engineer-until the day it cracks and everything above it fails.
The November 2025 Cloudflare outage offers several clear lessons for business leaders thinking strategically about infrastructure resilience. Let me translate these into an actionable roadmap.
Before we dive into specific recommendations, you need to understand three forces that are making infrastructure dependency both more valuable and more dangerous simultaneously:
🔮 Accelerating Consolidation: The infrastructure market continues consolidating around three primary providers-Cloudflare, Amazon Web Services, and Microsoft Azure-with smaller players struggling to compete on scale and cost efficiency
🔧 Automation Double-Edge: Rapid deployment systems that can propagate changes globally in seconds enable faster innovation and security responses but also mean errors cascade instantly before human intervention is possible
📈 Deepening Dependencies: Modern applications increasingly rely on dozens of interconnected services, creating dependency chains where a failure in one link can cascade unpredictably through the entire stack
Betsy Cooper, Founding Director of the Aspen Policy Academy, introduced a compelling analogy in analyzing this outage: “We need the equivalent of digital backup generators.” Just as hospitals and data centers maintain backup power systems for when the electrical grid fails, businesses need redundant infrastructure capabilities for when primary cloud providers experience disruptions.
What does this mean practically? It doesn’t mean running duplicate infrastructure for everything-that’s prohibitively expensive and complex. It means strategic redundancy for mission-critical services and rapid failover capabilities when primary systems fail.
Here’s a concrete roadmap for improving your infrastructure resilience over the next quarter:
1️⃣ Conduct a Dependency Audit (Week 1-2): Map all critical business services and identify which infrastructure providers they depend on, including indirect dependencies through your software vendors. Create a visual “dependency map” showing single points of failure. Ask your technical team: “If Cloudflare/AWS/Azure went offline for six hours today, which of our services would fail?”
2️⃣ Calculate Your Exposure (Week 3-4): Quantify the business impact of infrastructure outages by estimating hourly revenue loss, productivity costs, and SLA penalties for each critical service. This becomes your business case for investing in resilience. Be realistic-assume outages will happen during peak business hours, not conveniently at 3am on a Sunday.
3️⃣ Implement Multi-Vendor Strategy for Critical Services (Week 5-8): For your highest-impact services, implement multi-CDN approaches with DNS-based load balancing and automatic failover. This doesn’t mean abandoning your primary provider-it means having a tested backup that activates automatically when the primary fails. Prioritize based on business impact, not technical complexity.
4️⃣ Establish Independent Monitoring (Week 9-10): Ensure your monitoring infrastructure doesn’t depend on the services being monitored. Use multiple monitoring providers in different data centers to detect outages quickly and differentiate between your issues and infrastructure provider issues.
5️⃣ Test Your Backup Plans (Week 11-12): Actually test your failover procedures under realistic conditions, not just document them. Schedule a “fire drill” where you deliberately switch to backup infrastructure and verify that everything works. Most disaster recovery plans look great on paper but fail their first real test.
6️⃣ Budget for Quality Over Price (Ongoing): The cheapest infrastructure option is rarely the best value when you account for downtime costs. Allocate resources for reliability features, redundancy capabilities, and proven incident response rather than optimizing purely on monthly fees.
Here’s something that might surprise you: despite this catastrophic outage, I’d argue Cloudflare stock represents a reasonable investment at current levels around $196, down from its pre-outage price of $202. Why? Because the market reaction tells us something important about how investors assess infrastructure risk.
Cloudflare’s stock fell 7.0% at its worst point on November 18, but closed down just 2.8% after the company’s transparent communication and rapid service restoration. This relatively muted reaction-compare it to data breach incidents that can cause 20-30% declines-suggests investors view this as a recoverable operational incident rather than a fundamental company failure.
More importantly, the underlying financials remain strong. Q3 2025 revenue grew 31% year-over-year to $562 million, while net losses decreased dramatically from $15.3 million to just $1.3 million, showing clear movement toward profitability. With a majority of analysts maintaining “Buy” ratings, the market is essentially saying: “They screwed up, they owned it, they’re fixing it, and the long-term growth story remains intact.”
For business leaders, this teaches a valuable lesson about crisis response: transparency, rapid remediation, and concrete prevention measures can contain reputational damage even after spectacular operational failures. CEO Matthew Prince’s decision to personally author a detailed technical postmortem within 12 hours-including the actual code that failed-demonstrated the kind of accountability that rebuilds trust quickly.
The November 18, 2025 Cloudflare outage was not just a technical failure-it was a wake-up call about the hidden architecture of modern business operations. We’ve built our digital economy on a foundation of concentrated infrastructure that delivers remarkable efficiency and performance under normal conditions but creates systemic risk during failure scenarios.
The question facing business leaders is not whether similar outages will occur again-in systems of this complexity and scale, they inevitably will-but whether your organization will be prepared when they do. The companies that emerge strongest from the next major infrastructure disruption will be those that invested in strategic redundancy, maintained independent monitoring, tested their backup procedures, and treated infrastructure resilience as a board-level concern rather than an IT afterthought.
As one Reddit user aptly observed during the outage, the internet remains “held together with duct tape and prayer.” The challenge for this generation of business leaders is transforming that duct tape into engineered resilience while maintaining the speed, innovation, and accessibility that have made the modern web transformative. The cost of this transformation is measured in millions. The cost of ignoring it, as we learned on November 18, is measured in billions.

Alexander Timokhin
CEO

A Beginner’s Guide to Subnetting IPv4 and IPv6 Addresses Subnetting is a critical

Why IPv4 Leasing Is Becoming the Smart Choice for Businesses in 2025 1. Introduction
As CEO of InterLIR, I’ve witnessed firsthand how network isolation strategies

What is an ASN? ASN stands for Autonomous System Number. It is a unique identifier

Anycast DNS: A Leader’s Guide to Protecting Your Digital Infrastructure Executive

RPKI Certification: A Leader’s Guide to Internet Routing Security Executive

Executive Summary: What You Need to Know 🎯 Strategic Importance – Internet

When AWS DynamoDB failed in October 2025, thousands of businesses discovered that

Executive Summary: What You Need to Know 🎯 IP reputation directly impacts your
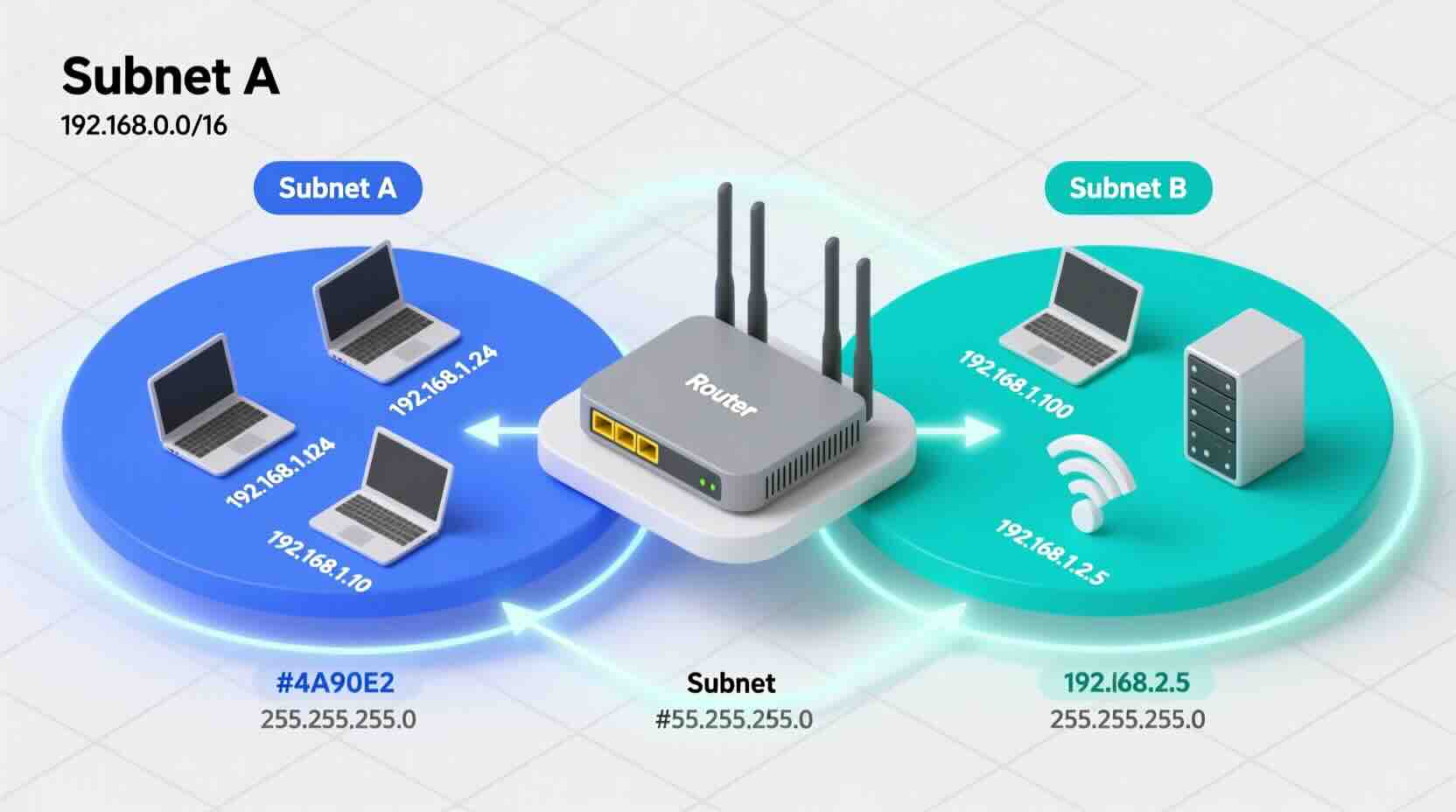
Mastering Subnetting and Routing for Modern Networks Why Subnetting Matters in Today’s


