BGP Zombies and Excessive Path Hunting: How Undead Routes Disrupt Internet Traffic
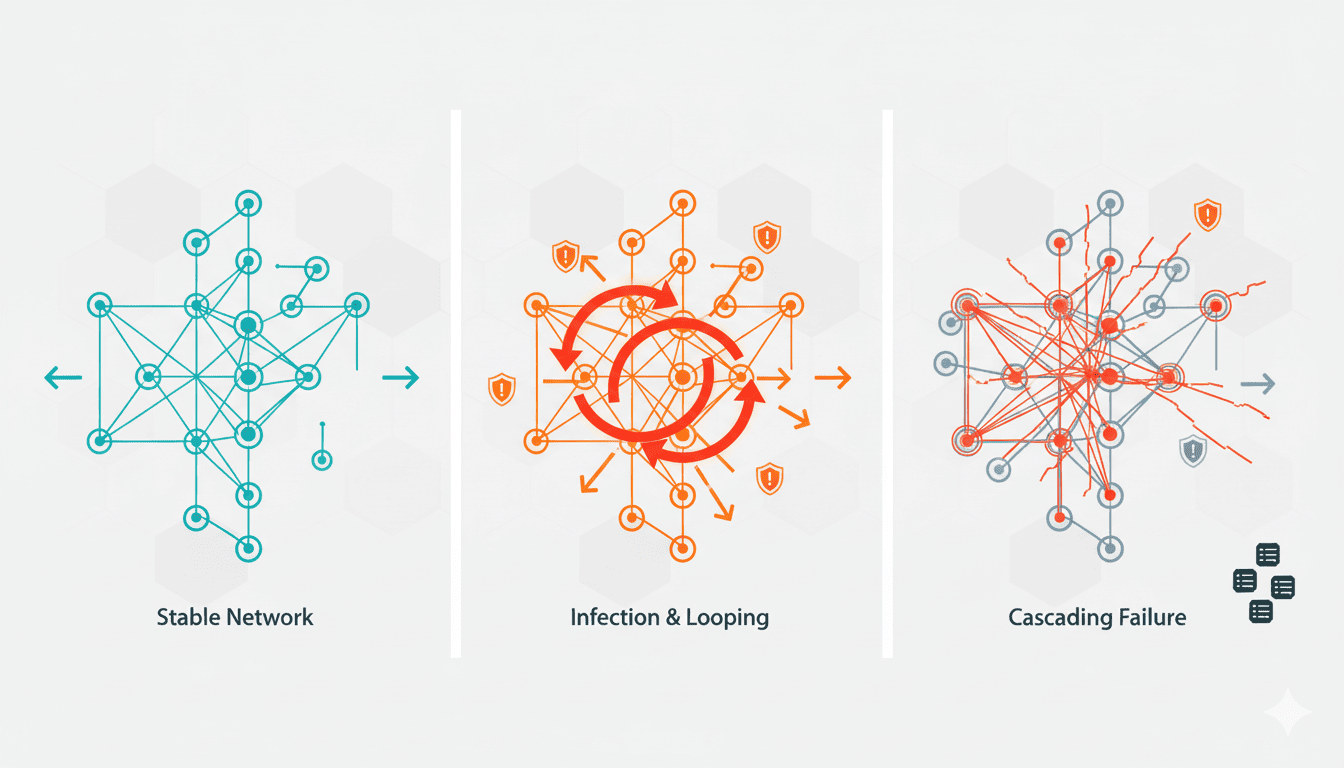
In the vast, interconnected landscape of the internet, routing protocols play a crucial role in directing traffic efficiently between networks. When these protocols malfunction, they can create unusual phenomena with significant operational impacts. One such phenomenon, appropriately named “BGP zombies,” has been affecting internet routing and causing headaches for network operators worldwide. At InterLIR, where we specialize in IPv4 address management and network resource optimization, understanding these routing anomalies is essential for helping our clients maintain stable, efficient network operations.
As someone who works daily with organizations managing IP resources and network infrastructure, I’ve seen firsthand how routing instabilities can impact business operations. BGP zombies represent one of the more insidious challenges in modern internet routing-routes that refuse to die gracefully, creating cascading effects that can disrupt connectivity and degrade performance across vast portions of the internet.
Understanding BGP and Its Undead Routes
Border Gateway Protocol (BGP) serves as the foundation of internet routing, essentially functioning as the internet’s GPS system. It enables autonomous systems (ASes) to exchange routing information and determine optimal paths for traffic flow. For organizations acquiring IPv4 address blocks through marketplaces like InterLIR, proper BGP configuration and management becomes critical to ensuring those resources function effectively within the global routing infrastructure.
A BGP zombie is a route that persists in the Internet’s Default-Free Zone (DFZ) after it should have been withdrawn. These routes become “undead” when the withdrawal message fails to propagate fully across the network, causing packets to be routed incorrectly or trapped in loops. The consequences range from minor inefficiencies to significant outages affecting user experience across vast portions of the internet. For businesses relying on consistent network availability-a core concern we address at InterLIR-these routing anomalies can translate directly into revenue loss and customer dissatisfaction.
What Causes BGP Zombies?
Understanding the root causes of BGP zombies helps network operators implement preventive measures and respond effectively when issues arise:
🐛 Buggy router software – Implementation flaws in routing software can prevent proper processing of withdrawal messages. Even major router vendors occasionally release firmware with BGP processing bugs that contribute to zombie formation.
🐢 Route processing delays – Older or overloaded hardware may process BGP updates more slowly. As routing tables continue to grow-particularly in IPv4 space where we’ve seen significant fragmentation-processing demands increase correspondingly.
⚙️ Configuration settings – Certain BGP configurations can inadvertently prolong convergence times. Aggressive route dampening, misconfigured timers, or overly complex routing policies can all contribute to zombie persistence.
🌐 Network complexity – Highly interconnected networks with numerous peers increase the likelihood of zombies. Organizations with extensive peering arrangements face greater exposure to this phenomenon.
From our perspective at InterLIR, helping clients understand these technical factors is part of ensuring they can effectively manage the IPv4 resources they acquire. Network availability problems-which our mission centers on solving-often stem from routing instabilities like BGP zombies rather than simple address exhaustion.
The Path Hunting Process: How Zombies Form
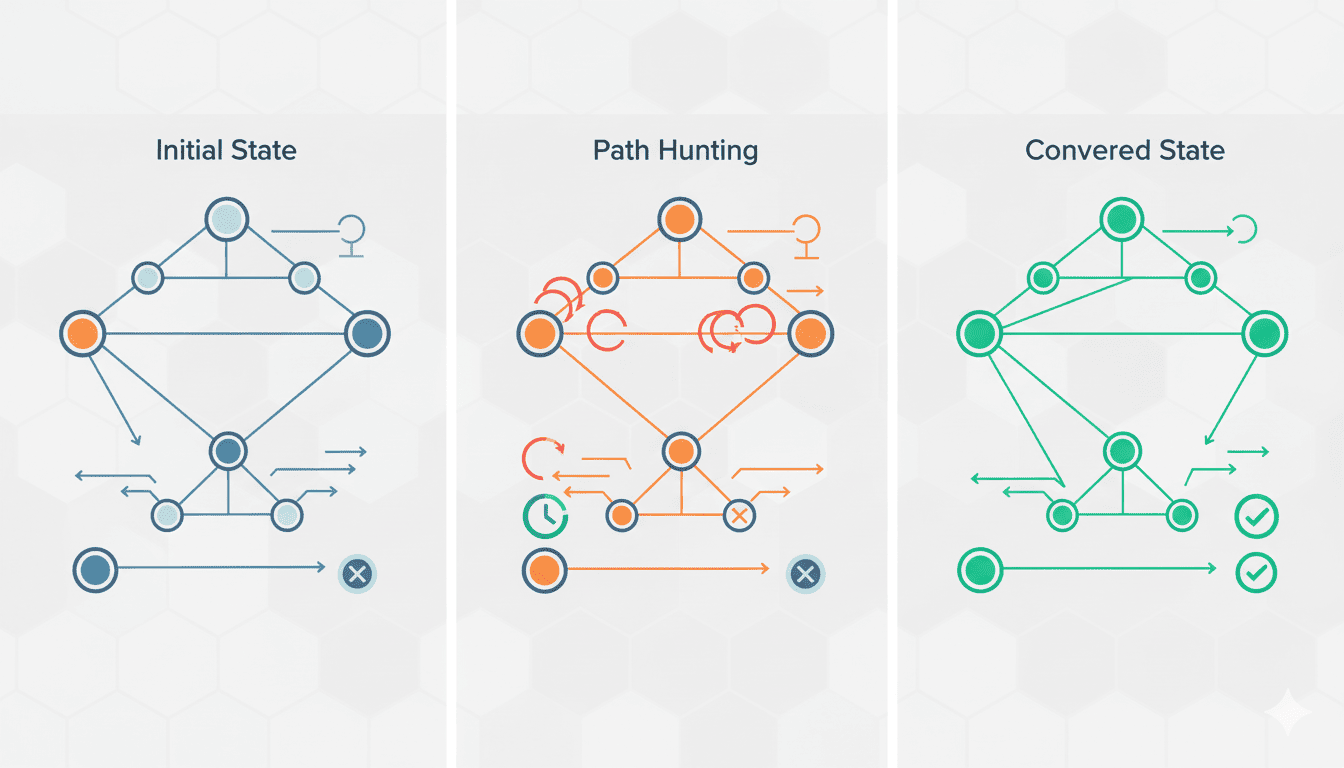
To understand BGP zombies, we must first grasp the concept of path hunting. Path hunting occurs when BGP routers search for the best route to a destination after a previously known route disappears. This process follows specific rules based on longest prefix matching (LPM) and various BGP attributes such as AS path length and local preference.
When a more-specific prefix (for example, a /24 in IPv4 space) is withdrawn, routers must fall back to less-specific routes (such as a /22 or /20) to maintain connectivity. This transition period, during which routers hunt for alternative paths, creates an opportunity for zombies to emerge. For organizations managing multiple IPv4 blocks with varying levels of specificity-a common scenario among our clients-understanding this mechanism becomes particularly important.
Anatomy of a Path Hunting Scenario
Consider this simplified scenario: a network announces two prefixes: 192.0.2.0/22 (less-specific) and 192.0.2.0/24 (more-specific). Initially, all traffic to addresses within the /24 range follows the more-specific route due to longest prefix matching rules. When the network withdraws the /24 announcement, all routers should eventually converge on using the /22 route for that traffic.
However, BGP convergence isn’t instantaneous. Some routers process the withdrawal faster than others, creating a temporary state where:
🔄 Some routers have already updated their tables and are using the /22 route
🧟♂️ Others still believe the /24 route exists and attempt to use it
🔄 Traffic gets redirected between routers trying to find a path that no longer exists
⚠️ Packets may loop indefinitely, experience excessive latency, or be dropped entirely
This inconsistency can lead to routing loops, excessive latency, or even packet loss until all routers converge on the new routing state. In my experience working with clients at InterLIR, these convergence delays often catch network operators by surprise, particularly when they’re implementing changes to their IP address announcements for the first time.
The MRAI Factor: Amplifying Path Hunting Time
The Minimum Route Advertisement Interval (MRAI) significantly contributes to the zombie problem. Specified in RFC4271, MRAI introduces an intentional delay-typically 30 seconds for eBGP updates-between consecutive BGP advertisements from a router. While this prevents excessive BGP message churn and potential route oscillation, it also extends the path hunting duration, potentially allowing zombies to persist longer.
This design trade-off highlights a fundamental challenge in BGP: balancing rapid convergence against routing stability. The 30-second MRAI timer made sense when the internet was smaller and less dynamic, but as networks have grown more complex and interconnected, this delay can feel like an eternity during critical routing changes.
Real-World Zombie Variants Observed in the Wild
Through controlled experiments and real-world observations, researchers at Cloudflare have identified several variants of BGP zombies with distinct characteristics and behaviors. Understanding these variants helps network operators diagnose and address zombie-related issues more effectively.
Variant A: Ghoulish Gateways
This zombie variant manifests between upstream Internet Service Providers (ISPs). When one router in a provider’s network processes withdrawal messages slower than others, routes can become stuck, creating loops between providers. These loops cause packets to bounce back and forth between networks, never reaching their destination.
For example, Cloudflare observed routing loops between two upstream partners after withdrawing a test prefix, with packets bouncing between provider networks for approximately six minutes before convergence-significantly longer than most operators would expect for normal BGP convergence. For businesses dependent on consistent connectivity, six minutes of routing instability can represent substantial service disruption.
This variant particularly affects organizations with multi-homed network architectures-a common configuration among enterprises managing their own IPv4 address space. When working with clients at InterLIR who are establishing their first autonomous system, we emphasize the importance of understanding these inter-provider dynamics.
Variant B: Undead LAN (Local Area Network)
The second variant occurs entirely within a single network. When a route is withdrawn, each device within the network must individually process the withdrawal. If one router lags behind, it can create internal routing loops where packets circulate endlessly between routers within the same organization’s infrastructure.
These internal loops persist until all devices within the network reach a consistent view of the routing table. While typically shorter-lived than inter-provider zombies, internal zombies can be particularly frustrating because they occur within infrastructure that operators directly control and expect to behave predictably.
Zombie Lifespans: IPv4 vs. IPv6
Interestingly, research has revealed that BGP zombies exhibit different behaviors across IP protocols, with significant implications for network planning and operations:
| Protocol | Typical Zombie Lifespan | Observed Maximum Impact | Routing Table Size Factor |
|---|---|---|---|
| IPv4 | 6-11+ minutes | 10+ minutes in major networks | ~950,000+ prefixes globally |
| IPv6 | 2-4 minutes | 4 minutes in Tier-1 networks | ~180,000+ prefixes globally |
The disparity likely stems from the significantly larger number of IPv4 prefixes in the global routing table compared to IPv6. With more routes to process, BGP speakers may take longer to converge after withdrawals in IPv4 space. This observation has particular relevance for our work at InterLIR, where we focus specifically on IPv4 address markets. The larger IPv4 routing table and longer convergence times mean that organizations managing IPv4 resources face greater exposure to zombie-related disruptions.
Network Interconnection Impact on Zombie Duration
Research has also highlighted how network interconnection levels affect zombie persistence. Highly peered networks with thousands of global connections show longer zombie lifespans when withdrawing routes. Withdrawals from less well-peered networks resulted in faster convergence times-though even these “faster” times (around 20 seconds) can still cause significant operational impacts.
This finding creates an interesting paradox: the more well-connected and resilient your network becomes through extensive peering, the more susceptible you may be to prolonged BGP zombie events. Organizations expanding their network footprint need to balance connectivity benefits against increased convergence complexity.
Mitigating the BGP Zombie Outbreak
Based on research findings that withdrawing more-specific prefixes leads to longer-lived zombies, several practical approaches can reduce their impact. At InterLIR, we work with clients to implement these strategies as part of comprehensive network availability solutions.
Internal Network Improvements
1️⃣ Graceful traffic forwarding – Implementing BGP forwarding improvements that allow more graceful withdrawal of traffic, even when routes are erroneously pointing toward a network. This might include maintaining forwarding state temporarily after route withdrawal to allow stragglers to converge.
2️⃣ Tunneled connectivity – Maintaining ability to deliver traffic over tunneled connections or private network interconnects even when public routing is compromised. GRE tunnels, MPLS, or SD-WAN overlays can provide alternative paths during BGP instability.
3️⃣ BGP community functionality – Utilizing BGP communities like no-export to control route propagation during withdrawal scenarios. Proper community tagging allows more granular control over how routes propagate and withdraw across the internet.
4️⃣ Route monitoring and alerting – Implementing real-time monitoring systems that detect anomalous routing behavior and alert operators to potential zombie situations before they cause widespread impact.
Recommended Multi-Step Draining Process
For scenarios where organizations need to drain traffic from on-demand BGP prefixes without introducing route loops or blackhole events, research suggests this approach:
1️⃣ Start with prefix announcement – Organization already announces example prefix (e.g., 198.18.0.0/24) from a provider network or transit connection
2️⃣ Introduce same-length announcement – Organization begins natively announcing the same-length prefix from their own network to destination ISPs, creating redundant path availability
3️⃣ Verification period – Monitor routing tables across multiple vantage points to confirm the new announcement has propagated globally and is being accepted by major transit providers
4️⃣ Withdrawal after stabilization – After sufficient time (typically 5-10 minutes allowing for propagation), signal withdrawal from the original provider network
5️⃣ Post-withdrawal monitoring – Continue monitoring for zombie routes and convergence issues for at least 15-20 minutes after withdrawal
This method prevents excessive path hunting because routers don’t need to aggressively seek a missing more-specific prefix; they can immediately fall back to the same-length announcement that already exists in the routing table. When advising clients at InterLIR on IP address management strategies, we emphasize this type of careful, methodical approach to routing changes.
Industry Implications and Future Directions
BGP zombies represent a significant challenge for the internet’s routing infrastructure, particularly as networks become more interconnected and traffic volumes increase. The research conducted has broader implications for network operators, content delivery networks, and the internet ecosystem as a whole-implications that directly affect how we approach network availability problems at InterLIR.
Recommendations for Network Operators
Based on current research and operational experience, network operators should consider the following practices:
🔍 Monitoring and detection – Implement monitoring systems to detect stuck routes and BGP zombies in your network. Tools like BGPmon, RIPE RIS, or RouteViews can provide visibility into routing behavior across multiple vantage points.
⚙️ MRAI tuning – Consider adjusting MRAI timers based on network size and connectivity patterns. While the default 30-second timer works for many scenarios, some networks may benefit from more aggressive or conservative settings.
🔄 Route propagation design – When possible, design announcement/withdrawal strategies that minimize path hunting. Avoid unnecessary prefix fragmentation and maintain consistent announcement policies.
🧪 Testing procedures – Develop testing frameworks to identify zombie-prone routing configurations before deployment. Lab environments or isolated test networks can reveal potential issues before they affect production traffic.
📚 Documentation and runbooks – Create detailed procedures for routing changes, including rollback plans and expected convergence timelines. Clear documentation helps operations teams respond effectively during incidents.
Industry Standardization Efforts
The findings highlight the need for broader industry collaboration on BGP best practices and potential protocol improvements. Some areas for standardization might include:
📋 Withdrawal procedures – Standardized approaches for graceful route withdrawals that minimize zombie formation and reduce convergence time
🛡️ Zombie protection mechanisms – Protocol extensions to prevent or quickly identify zombie routes, potentially including explicit acknowledgment mechanisms for withdrawals
📊 Measurement standards – Common metrics and methodologies for quantifying BGP convergence performance, enabling better comparison across networks and equipment vendors
🔧 Vendor implementation guidelines – Clearer specifications for how router vendors should implement BGP update processing to minimize zombie-prone behavior
At InterLIR, we stay engaged with these industry developments because they directly impact how effectively organizations can utilize the IPv4 resources they acquire through our marketplace. Network availability isn’t just about having addresses-it’s about ensuring those addresses function reliably within the global routing infrastructure.
Practical Considerations for IPv4 Resource Management
For organizations acquiring IPv4 address blocks-whether through transfer markets like InterLIR or other means-understanding BGP zombies has practical implications for resource deployment and management:
Prefix Size and Announcement Strategy
The size and specificity of announced prefixes directly affects zombie susceptibility. Organizations should consider:
📏 Minimum announcement size – While /24 is the minimum generally accepted prefix size in IPv4, announcing larger blocks when possible reduces routing table fragmentation and may improve convergence behavior
🎯 Specific vs. aggregate announcements – Carefully evaluate whether traffic engineering requirements truly necessitate more-specific announcements, as these create greater zombie risk during changes
🔀 Deaggregation strategy – If deaggregation is necessary, implement it with full understanding of the convergence implications and appropriate monitoring
Provider Selection and Peering Strategy
The research on zombie duration across different network interconnection levels suggests that provider selection matters:
🌐 Transit provider evaluation – When selecting upstream providers, consider their BGP implementation quality and convergence performance, not just bandwidth and pricing
🤝 Peering relationships – While extensive peering provides redundancy and performance benefits, recognize that it may extend convergence times during routing changes
📡 Multi-homing considerations – Multi-homed configurations provide resilience but require careful coordination during routing changes to avoid zombie formation
BGP zombies represent a fascinating intersection of network protocol design, distributed systems behavior, and operational challenges. These undead routes demonstrate how even small inconsistencies in routing state propagation can lead to significant real-world impacts on internet traffic. For organizations managing IP resources-particularly IPv4 addresses in an increasingly fragmented routing landscape-understanding and mitigating BGP zombies is essential for maintaining reliable network operations.
Throughout my work at InterLIR, I’ve seen how routing instabilities can undermine even the most carefully planned network deployments. Our mission of solving network availability problems extends beyond simply facilitating IPv4 address transfers; it encompasses helping clients understand the technical complexities of operating those resources effectively within the global internet infrastructure. BGP zombies exemplify the type of subtle but impactful challenge that requires both technical knowledge and operational discipline to address.
The research findings provide valuable insights into the formation, behavior, and mitigation of BGP zombies. By understanding the path hunting process and implementing appropriate withdrawal strategies-such as the multi-step draining process and internal forwarding improvements-network operators can reduce the likelihood and impact of zombie outbreaks. The differences between IPv4 and IPv6 zombie behavior, with IPv4 showing significantly longer convergence times, underscore the ongoing challenges in managing the legacy protocol that continues to dominate internet traffic.
As the internet continues to grow in complexity and interconnectedness, addressing BGP zombie phenomena will become increasingly important for maintaining a stable, reliable global network. The practical mitigation strategies outlined-from graceful forwarding mechanisms to careful announcement planning-represent actionable steps that organizations can implement today. However, longer-term solutions will require continued research, protocol improvements, and industry collaboration to fundamentally address the architectural factors that enable zombie formation.
For network operators, the key takeaway is clear: routing changes require careful planning, methodical execution, and comprehensive monitoring. The days of simply announcing or withdrawing prefixes without considering convergence behavior are behind us. Modern network operations demand a more sophisticated approach that accounts for the distributed, asynchronous nature of BGP convergence and the potential for zombie routes to disrupt traffic flow.
The fight against BGP zombies remains an ongoing battle-one that requires vigilance, technical innovation, and collaborative effort across the internet’s operational community. At InterLIR, we’re committed to supporting our clients through these challenges, ensuring that the IPv4 resources they acquire deliver the network availability and reliability their businesses demand.