Als 20 % des Internets ausfielen: Ein Leitfaden für Führungskräfte zum Verständnis von Infrastrukturrisiken
Zusammenfassung: Was Sie wissen müssen
🎯 Konzentration kritischer Infrastruktur: Ein einziger sechsstündiger technischer Ausfall bei Cloudflare unterbrach am 18. November 2025 20 % des globalen Internetverkehrs und betraf alles von KI-Chatbots bis zu McDonald’s-Bestellkiosken – was die gefährliche Abhängigkeit von einer Handvoll Infrastrukturanbieter offenlegte.
💰 Massive wirtschaftliche Auswirkungen: Der Ausfall verursachte Gesamtverluste von 5 bis 15 Milliarden US-Dollar pro Stunde für alle betroffenen Unternehmen, wobei einzelne Unternehmen je nach Größe 300.000 bis 1 Million US-Dollar pro Stunde verloren.
🚀 Strategisches Handeln erforderlich: Führungskräfte müssen umgehend ihre Infrastrukturabhängigkeiten prüfen, Multi-Vendor-Redundanzstrategien implementieren und „digitale Notstromaggregate“ für den Fall vorbereiten, dass – nicht ob – der nächste große Ausfall eintritt.
⚠️ Börsenlektion: Trotz des katastrophalen operativen Versagens fiel die Aktie von Cloudflare zum Börsenschluss nur um 2,8 %, was zeigt, dass Investoren Infrastrukturresilienz als beherrschbares Risiko betrachten, wenn Unternehmen mit Transparenz und konkreten Präventionsmaßnahmen reagieren.
Warum sollten nicht-technische Führungskräfte sich für einen „technischen“ Ausfall interessieren?
Lassen Sie mich mit einem einfachen Szenario beginnen, das in Ihrem Unternehmen am 18. November 2025 wahrscheinlich eingetreten ist. Ihr Marketing-Team konnte nicht auf die Design-Tools in Canva zugreifen. Ihre Kundendienstplattform fiel aus. Ihre Entwickler konnten ChatGPT oder Claude nicht für Coding-Hilfe erreichen. Ihre Mitarbeiter konnten keinen Urlaub buchen, weil das HR-System nicht funktionierte. Und wenn Sie Einzelhandelsstandorte betreiben, zeigten Ihre Selbstbedienungskiosks möglicherweise Fehlerseiten anstatt Bestellungen entgegenzunehmen.
Alle diese Ausfälle – bei völlig unterschiedlichen Unternehmen und Plattformen – hatten eine einzige Ursache: Cloudflare, das unsichtbare Infrastrukturunternehmen, das etwa 20 % des gesamten Internetverkehrs leitet, erlebte einen katastrophalen technischen Ausfall, der fast sechs Stunden dauerte. Man kann sich Cloudflare wie das Stromnetz für das moderne Internet vorstellen. Wenn das Netz ausfällt, spielt es keine Rolle, wie gut Ihr Gebäude gestaltet ist oder wie viel Sie in Ihre Betriebsabläufe investiert haben – die Lichter gehen einfach nicht an.
Einfach ausgedrückt: Cloud-Infrastrukturanbieter wie Cloudflare sind das digitale Äquivalent zu Versorgungsunternehmen – unsichtbar, bis sie ausfallen, aber absolut kritisch für den Geschäftsbetrieb. Sie entscheiden darüber, ob Ihre Kunden Ihre Website erreichen können, ob Ihre Anwendungen ordnungsgemäß funktionieren und ob Ihre digitalen Dienste während entscheidender Geschäftszeiten zugänglich bleiben. Wenn sie ausfallen, fällt Ihr Unternehmen mit ihnen aus, unabhängig davon, wie viel Sie in Ihre eigene Technologie investiert haben.
Was diesen Vorfall zu einem Wendepunkt macht, ist nicht nur sein Ausmaß – obwohl die Betroffenheit von Hunderten Millionen Nutzern und Verluste in Milliardenhöhe dies sicherlich rechtfertigen –, sondern was er über die verborgenen Architekturrisiken in modernen Geschäftsabläufen offenbart. Wir haben so viel unserer digitalen Infrastruktur auf eine Handvoll Anbieter konzentriert, dass deren Ausfälle nun gleichzeitig ganze Wirtschaftssektoren betreffen. Dieses Konzentrationsrisiko zu verstehen und sich darauf vorzubereiten, ist keine Option mehr – es ist eine grundlegende Anforderung der Geschäftskontinuität.
In dieser Anleitung werde ich die Ereignisse vom 18. November 2025 aufschlüsseln, die technische Komplexität in Geschäftssprache übersetzen, erklären, warum dies für Ihre strategische Planung wichtig ist, und einen klaren Fahrplan zum Schutz Ihres Unternehmens vor ähnlichen Störungen in Zukunft bieten. Beginnen wir damit, zu verstehen, wie es zu dieser prekären Situation gekommen ist.
Wie wurden wir so abhängig von einer Handvoll Infrastrukturunternehmen?
Um die heutige Anfälligkeit der Infrastruktur zu verstehen, müssen wir in die Anfänge des kommerziellen Internets in den 1990er Jahren zurückgehen. Stellen Sie sich das Internet als eine Kleinstadt vor, in der jedes Unternehmen seine eigenen Server betrieb, seine eigene Sicherheit verwaltete und sein eigenes Routing der Datenströme handhabte. Dieser Ansatz funktionierte gut, als es Tausende von Websites gab, erforderte jedoch erhebliche technische Expertise und Kapitalinvestitionen, die die meisten Unternehmen nicht aufrechterhalten konnten.
Von einzelnen Generatoren zu einem gemeinsamen Stromnetz
Als das Internet in seinem Umfang explodierte – von Tausenden Websites zu Milliarden – kam es zu einer natürlichen Konsolidierung. Unternehmen wie Cloudflare, Amazon Web Services und Microsoft Azure etablierten sich als die „Stromversorger“ des digitalen Zeitalters. Sie boten an, die gesamte komplexe Infrastrukturarbeit zu übernehmen – Sicherheit, Geschwindigkeitsoptimierung, Datenverkehrsleitung, DDoS-Schutz – damit sich Unternehmen auf ihre Kernkompetenzen konzentrieren konnten, anstatt Server zu verwalten.
Diese Veränderung war enorm vorteilhaft. Ein kleines E-Commerce-Startup konnte dieselbe Unternehmensinfrastruktur wie Fortune-500-Unternehmen zu einem Bruchteil der Kosten nutzen. Websites luden schneller. Die Sicherheit verbesserte sich drastisch. Die technischen Hürden für die Gründung eines digitalen Unternehmens sanken erheblich. Man kann es sich so vorstellen, als würde man von einzelnen Generatoren für jedes Gebäude zu einem zuverlässigen Stromnetz wechseln – es war effizienter, kostengünstiger und im Allgemeinen zuverlässiger.
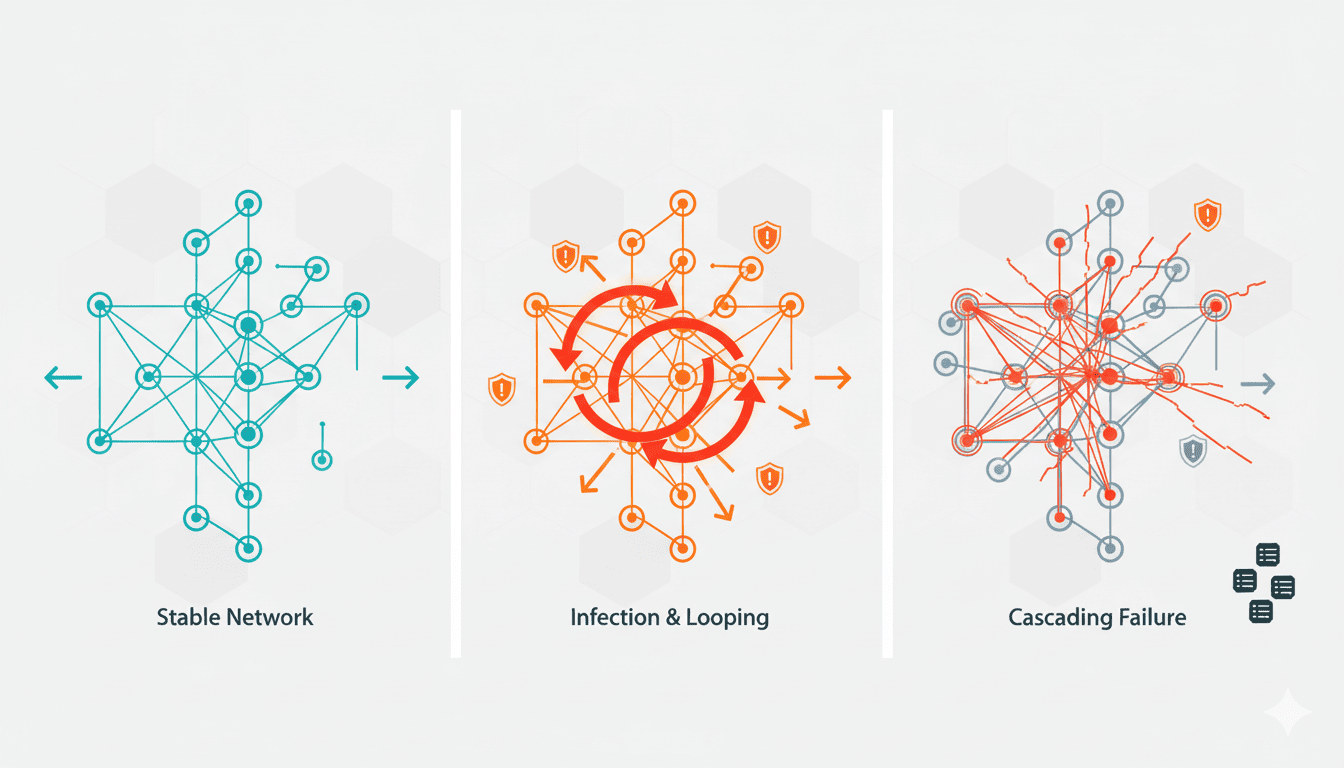
Allerdings hat diese Konsolidierung eine neue Risikokategorie geschaffen, die wir erst jetzt vollständig erfassen. Wenn sich alle an dasselbe Netz anschließen, betrifft ein Ausfall dieses Netzes alle gleichzeitig. Vor zwanzig Jahren, wie der Infrastrukturexperte Mike Chapple anmerkt, waren einzelne Dienstausfälle häufig – man konnte eine Woche mit mindestens einem ausgefallenen IT-Dienst rechnen. Doch jeder Ausfall betraf nur dieses eine Unternehmen. Heute haben wir durch Konsolidierung eine bemerkenswerte Gesamtzuverlässigkeit erreicht, aber ein neues Risiko geschaffen: Wenn einer dieser Infrastruktur-Giganten stolpert, fällt gleichzeitig 20 % des Internets aus.
Die Zahlen verdeutlichen diese Konzentration. Cloudflare allein verarbeitet unter normalen Bedingungen 81 Millionen HTTP-Anfragen pro Sekunde. Rund 35 % der Fortune-500-Unternehmen sind auf deren Dienste angewiesen. Etwa 32 % der 10.000 meistbesuchten Websites weltweit nutzen deren Infrastruktur. Wir haben im Wesentlichen einen beträchtlichen Teil der globalen digitalen Wirtschaft auf einer einzigen Plattform platziert – was für die Effizienz großartig, für die Resilienz jedoch erschreckend ist.
Was ist eigentlich am 18. November 2025 passiert?
Lassen Sie mich den technischen Ausfall in eine Geschäftsanalogie übersetzen, die verdeutlicht, was schiefgelaufen ist. Stellen Sie sich vor, Sie leiten ein globales Logistikunternehmen mit 330 Vertriebszentren weltweit. Alle fünf Minuten sendet Ihre Zentrale aktualisierte Versandanweisungen an alle Zentren. Diese Anweisungen sind normalerweise von überschaubarer Größe – etwa 60 Seiten Anleitungen.
Die Konfigurationsdatei, die zu groß wurde
Am Morgen des 18. November führte eine gut gemeinte Änderung Ihrer Datenbanksicherheitseinstellungen unbeabsichtigt dazu, dass das System Versanddaten aus zwei statt einer Quelle abrief. Plötzlich verdoppelte sich die Größe dieser Anweisungsdateien auf über 200 Seiten – mehr, als Ihre Distributionszentren verarbeiten konnten. Das System in jedem Zentrum versuchte, diese überdimensionierten Anweisungen zu laden, überschritt seine Speicherkapazität und stürzte vollständig ab. Keine Bestellungen konnten bearbeitet werden. Keine Sendungen konnten ausgeliefert werden. Der gesamte Betrieb kam weltweit zum Erliegen.
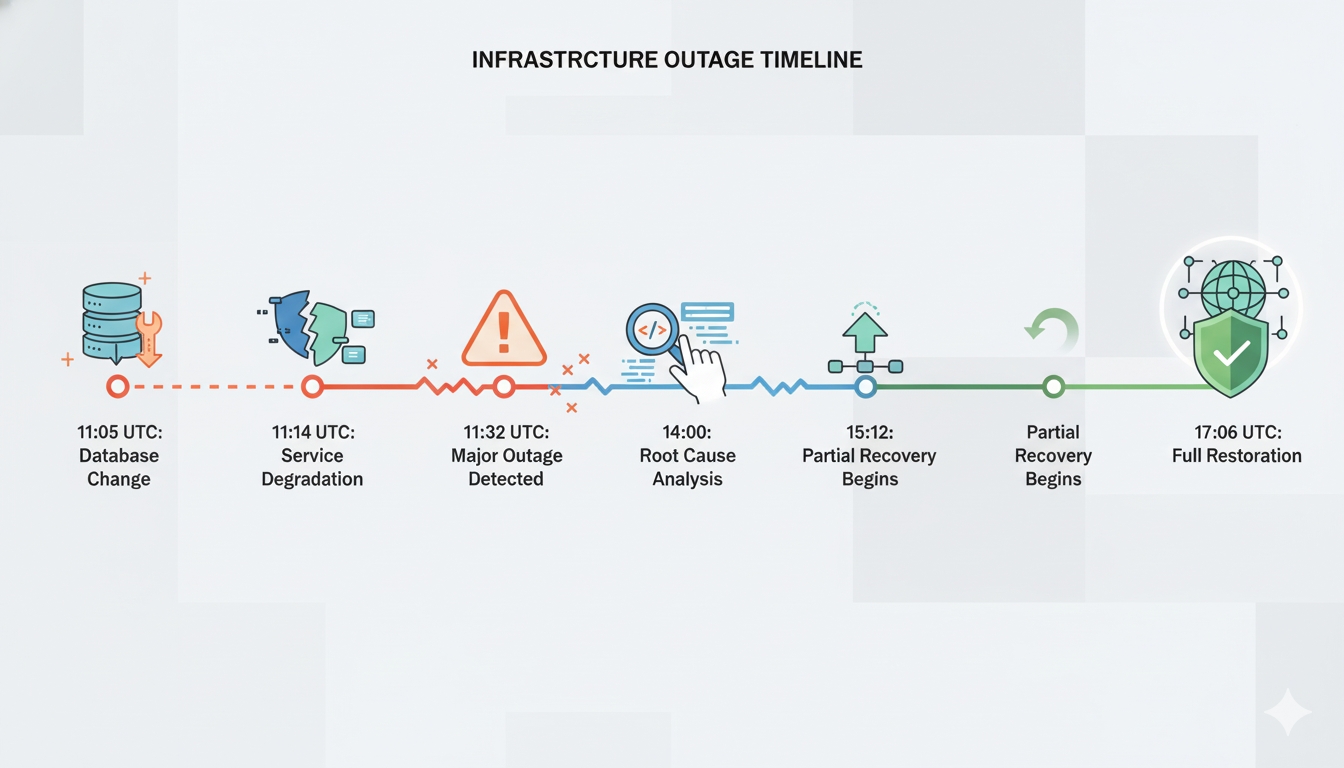
Genau das ist im Wesentlichen bei Cloudflare passiert. Um 11:05 UTC nahmen sie eine routinemäßige Änderung der Datenbankberechtigungen vor, die die Sicherheit verbessern sollte – vergleichbar mit einem Austausch der Schlösser. Diese Änderung löste eine unerwartete Folge aus: Eine Konfigurationsdatei, die von ihrem Bot-Management-System verwendet wird, begann, doppelte Daten abzurufen. Die Dateigröße explodierte von etwa 60 auf über 200 Merkmale. Diese überdimensionierte Datei wurde innerhalb von Sekunden über ihr schnelles Bereitstellungssystem an alle 330+ Rechenzentren verteilt.
Warum Geschwindigkeit zum Feind wurde
Hier zeigten sich die Effizienzgewinne moderner Infrastrukturen als Nachteil. Cloudflares Bereitstellungssystem kann Änderungen in etwa Sekunden global verbreiten – eine beeindruckende technische Leistung, die schnelle Sicherheitsreaktionen ermöglicht. Doch dieselbe Geschwindigkeit bedeutet, dass sich Fehler ebenfalls sofort über alle Rechenzentren verbreiten, bevor menschliche Bediener eingreifen können. Als das Problem um 11:31 UTC bemerkt wurde – nur 11 Minuten nach den ersten Fehlern – war die fehlerhafte Konfiguration bereits mehrfach weltweit verteilt worden.
Die Diagnose wurde zusätzlich erschwert, weil das Fehlermuster intermittierend auftrat. Dienste funktionierten fünf Minuten lang, fielen dann für fünf Minuten aus und arbeiteten anschließend wieder. Dieses Wechselmuster ähnelte den Merkmalen eines Cyberangriffs, weshalb das Incident-Response-Team zunächst die falsche Ursache untersuchte. Erst um 14:24 UTC – mehr als drei Stunden nach Beginn des Ausfalls – konnte die Grundursache identifiziert und das automatisierte System daran gehindert werden, überdimensionierte Konfigurationsdateien zu erzeugen.
Die menschlichen Kosten eines technischen Versagens
Das Ausmaß der Störung ging weit über das hinaus, was man von einem „technischen“ Problem erwarten würde. Große Plattformen wie X (Twitter), ChatGPT, Spotify, Discord, Zoom und Shopify fielen gleichzeitig aus. Doch die wirklich eindrucksvollen Auswirkungen zeigten sich in physischen Unternehmen: McDonald’s-Restaurants konnten keine Bestellungen über ihre Kiosks entgegennehmen. Kindertagesstätten konnten Kinder nicht elektronisch ein- oder auschecken. Verkehrssysteme verloren ihre Echtzeit-Informationsanzeigen. Mitarbeiter von Unternehmen hatten keinen Zugang zu HR-Systemen, um Urlaub zu beantragen.
Sogar die Überwachungssysteme versagten. DownDetector – die Website, die Nutzer verwenden, um zu prüfen, ob andere Seiten ausgefallen sind – war selbst offline, weil sie ebenfalls auf Cloudflare angewiesen war. Dies führte zu einer surrealen Situation, in der Nutzer keine zuverlässige Möglichkeit hatten, zu bestätigen, ob ihre Probleme isoliert oder Teil eines größeren Ausfalls waren, was zu Verwirrung und Angst auf Social-Media-Plattformen beitrug.
Was sind die wahren geschäftlichen Kosten von Infrastrukturabhängigkeit?
Wenn ich diesen Vorfall mit Führungskräften bespreche, lautet die erste Frage immer: „Wie viel hat das tatsächlich gekostet?“ Die Antwort zeigt, warum Infrastruktur-Resilienz ein Thema auf Vorstandsebene sein muss und nicht nur ein IT-Problem.
Der versteckte Multiplikatoreffekt gleichzeitiger Ausfälle
Forschungsergebnisse zu Ausfallkosten zeigen, dass 93 % der großen Unternehmen Ausfallkosten von über 300.000 US-Dollar pro Stunde verzeichnen, während 48 % Kosten von über einer Million US-Dollar pro Stunde melden. Diese Zahlen spiegeln jedoch einzelne Unternehmensausfälle wider. Wenn Tausende von Unternehmen gleichzeitig offline gehen, addieren sich die wirtschaftlichen Auswirkungen nicht – sie multiplizieren sich.
Analysten schätzen den gesamtwirtschaftlichen Schaden auf 5 bis 15 Milliarden US-Dollar pro Stunde für alle betroffenen Unternehmen. Über die Dauer von sechs Stunden bedeutet dies potenzielle Gesamtverluste in Höhe von Hunderten von Millionen bis zu mehreren Milliarden Dollar. Lassen Sie mich aufschlüsseln, wo diese Kosten anfallen:
💸 Direkter Umsatzverlust: E-Commerce-Plattformen konnten während der Hauptgeschäftszeiten in verschiedenen globalen Zeitzonen keine Transaktionen verarbeiten – jede Minute Ausfallzeit bedeutet verlorene Verkäufe, die nie wieder aufgeholt werden können.
📉 Marketingverschwendung: Unternehmen mit aktiven Werbekampagnen zahlten weiterhin für Klicks und Impressionen, die auf Fehlerseiten statt auf funktionierende Websites führten – Marketingbudgets wurden ohne jegliche Rendite verbrannt.
🔥 Imageschaden: Studien zeigen, dass 88 % der Nutzer nach einer schlechten Erfahrung weniger wahrscheinlich auf eine Website zurückkehren, selbst wenn sie intellektuell verstehen, dass die Ursache ein Drittanbieterfehler war, den das Unternehmen nicht kontrollieren konnte.
⚖️ Vertragsstrafen: Service-Level-Agreements (SLAs) mit Kunden lösten Strafklauseln aus und erzwangen Gutschriften für verpasste Verfügbarkeitsgarantien.
👥 Produktivitätseinbruch: Hunderte Millionen Wissensarbeiter weltweit verloren den Zugang zu essenziellen Tools, viele konnten während der Ausfallzeit schlichtweg ihre Arbeit nicht verrichten.
📞 Kostenexplosion im Support: Kundensupport-Teams wurden mit Anfragen von Nutzern überhäuft, die nicht erkannten, dass das Problem weit verbreitet war, wodurch Ressourcen von normalen Betriebsabläufen abgezogen wurden.
Der Devisenhandelssektor: Eine detaillierte Fallstudie
Um dies zu konkretisieren, betrachten Sie die Auswirkungen auf Devisen- und CFD-Broker. Diese Plattformen ermöglichen unter normalen Bedingungen ein Handelsvolumen von etwa 1,58 Milliarden US-Dollar alle drei Stunden. Während des Cloudflare-Ausfalls erlebten mehrere Broker, darunter Monaxa, Skilling, Xtrade und FXPro, einen vollständigen Betriebsstillstand. Händler konnten nicht auf ihre Positionen zugreifen, keine Trades ausführen und nicht auf Marktbewegungen reagieren. Das gesamte Handelsvolumen in diesem dreistündigen Fenster – etwa 1 % ihres typischen Monatsvolumens – verschwand einfach.
Ebenso meldeten Kryptobörsen während der Spitzenzeit des Ausfalls erhebliche Rückgänge der Handelsvolumina. Die Aktivität auf NFT-Märkten ging fast auf Null zurück. Einige Blockchain-Layer-2-Netzwerke, die auf Cloudflare für die API-Konnektivität angewiesen waren, wurden vollständig unzugänglich, was die Ironie offenbarte, dass „dezentrale“ Anwendungen oft auf zentralisierter Infrastruktur basieren.
Warum „Es ist nicht unsere Schuld“ Ihr Geschäft nicht schützt
Hier ist die unbequeme Wahrheit, die mich als Berater nachts wach hält: Kunden interessieren sich nicht dafür, wer schuld am Ausfall war – sie kümmern sich nur darum, dass Ihr Dienst nicht funktionierte, als sie ihn brauchten. Wenn Ihre Website eine Cloudflare-Fehlerseite anzeigt, anstatt korrekt zu laden, trifft es den Ruf Ihrer Marke, auch wenn der technische Fehler in einer Infrastruktur auftrat, die Sie nicht kontrollieren.
Deshalb ist es ein strategischer Fehler, Infrastrukturanbieter als „Problem anderer“ zu betrachten. Ihre Zuverlässigkeit beeinflusst direkt die Kundenerfahrung, Ihren Umsatz und Ihre Wettbewerbsposition. Dies rein als technisches Problem und nicht als Geschäftsrisiko zu behandeln, ist so, als würde man annehmen, dass das Fundament eines Gebäudes nicht Ihre Sorge ist, weil Sie kein Statiker sind – bis es eines Tages Risse bekommt und alles darüber zusammenbricht.
Was sollten kluge Führungskräfte künftig anders machen?
Der Cloudflare-Ausfall im November 2025 bietet mehrere klare Lehren für Führungskräfte, die strategisch über Infrastruktur-Resilienz nachdenken. Lassen Sie mich diese in einen umsetzbaren Fahrplan übersetzen.
Die drei Megatrends verstehen, die das Infrastrukturrisiko prägen
Bevor wir uns mit konkreten Empfehlungen befassen, müssen Sie drei Kräfte verstehen, die die Infrastrukturabhängigkeit gleichzeitig wertvoller und gefährlicher machen:
🔮 Beschleunigte Konsolidierung: Der Infrastrukturmarkt konsolidiert sich weiterhin um drei Hauptanbieter – Cloudflare, Amazon Web Services und Microsoft Azure – während kleinere Anbieter mit Skalierung und Kosteneffizienz kämpfen.
🔧 Automatisierung mit zwei Seiten: Schnelle Bereitstellungssysteme, die Änderungen in Sekunden global verbreiten können, ermöglichen schnellere Innovationen und Sicherheitsreaktionen, bedeuten aber auch, dass Fehler sofort kaskadieren, bevor menschliches Eingreifen möglich ist.
📈 Vertiefende Abhängigkeiten: Moderne Anwendungen sind zunehmend auf Dutzende von vernetzten Diensten angewiesen, was Abhängigkeitsketten schafft, bei denen ein Ausfall eines Glieds unvorhersehbar durch den gesamten Stack kaskadieren kann.
Das „Digitale Notstromaggregat“-Framework
Betsy Cooper, Gründungsdirektorin der Aspen Policy Academy, führte eine einprägsame Analogie in der Analyse dieses Ausfalls ein: „Wir brauchen das Äquivalent digitaler Notstromaggregate.“ Genau wie Krankenhäuser und Rechenzentren Notstromsysteme für den Fall eines Stromausfalls vorhalten, benötigen Unternehmen redundante Infrastrukturkapazitäten für den Fall, dass primäre Cloud-Anbieter Störungen erfahren.
Was bedeutet das praktisch? Es bedeutet nicht, doppelte Infrastruktur für alles vorzuhalten – das wäre unerschwinglich teuer und komplex. Es bedeutet strategische Redundanz für missionkritische Dienste und schnelle Failover-Fähigkeiten, wenn primäre Systeme ausfallen.
Der 90-Tage-Aktionsplan eines Führungskraft
Hier ist ein konkreter Fahrplan, um die Resilienz Ihrer Infrastruktur im nächsten Quartal zu verbessern:
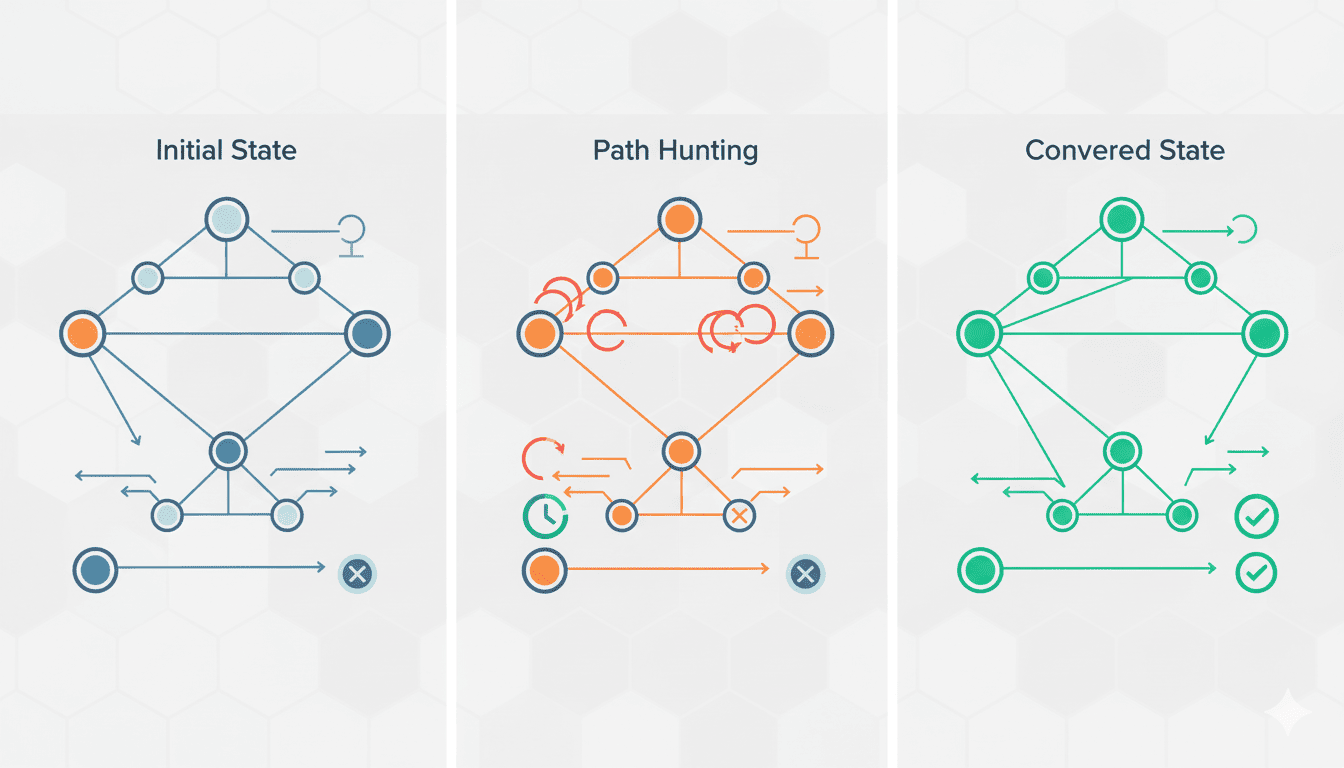
1️⃣ Durchführung einer Abhängigkeitsprüfung (Woche 1-2): Erfassen Sie alle geschäftskritischen Dienste und ermitteln Sie, von welchen Infrastrukturanbietern sie abhängen, einschließlich indirekter Abhängigkeiten über Ihre Softwareanbieter. Erstellen Sie eine visuelle „Abhängigkeitskarte“, die einzelne Ausfallpunkte aufzeigt. Fragen Sie Ihr technisches Team: „Wenn Cloudflare/AWS/Azure heute für sechs Stunden offline wäre, welche unserer Dienste würden ausfallen?“
2️⃣ Berechnen Sie Ihr Risiko (Woche 3-4): Quantifizieren Sie die geschäftlichen Auswirkungen von Infrastrukturausfällen, indem Sie den stündlichen Umsatzverlust, Produktivitätskosten und SLA-Strafen für jeden kritischen Dienst schätzen. Dies bildet Ihre Geschäftsgrundlage für Investitionen in Resilienz. Seien Sie realistisch – gehen Sie davon aus, dass Ausfälle während der Hauptgeschäftszeiten auftreten werden und nicht bequemerweise um 3 Uhr morgens an einem Sonntag.
3️⃣ Implementieren Sie eine Multi-Vendor-Strategie für kritische Dienste (Woche 5-8): Für Ihre wichtigsten Dienste sollten Sie Multi-CDN-Ansätze mit DNS-basiertem Load Balancing und automatischem Failover umsetzen. Das bedeutet nicht, Ihren primären Anbieter aufzugeben – es bedeutet, ein getestetes Backup zu haben, das automatisch aktiviert wird, wenn der primäre Anbieter ausfällt. Priorisieren Sie nach Geschäftsauswirkung, nicht nach technischer Komplexität.
4️⃣ Eigenständige Überwachung einrichten (Woche 9-10): Stellen Sie sicher, dass Ihre Überwachungsinfrastruktur nicht von den überwachten Diensten abhängt. Nutzen Sie mehrere Monitoring-Anbieter in verschiedenen Rechenzentren, um Ausfälle schnell zu erkennen und zwischen Ihren Problemen und denen des Infrastrukturanbieters zu unterscheiden.
5️⃣ Testen Sie Ihre Backup-Pläne (Woche 11-12): Testen Sie Ihre Failover-Prozeduren tatsächlich unter realistischen Bedingungen, nicht nur ihre Dokumentation. Planen Sie eine „Feuerübung“, bei der Sie absichtlich auf die Backup-Infrastruktur umschalten und überprüfen, ob alles funktioniert. Die meisten Notfallwiederherstellungspläne sehen auf dem Papier gut aus, versagen aber beim ersten echten Test.
6️⃣ Budget für Qualität statt Preis (fortlaufend): Die günstigste Infrastrukturoption ist selten die beste Wahl, wenn man die Kosten für Ausfallzeiten berücksichtigt. Weisen Sie Ressourcen für Zuverlässigkeitsfunktionen, Redundanzfähigkeiten und bewährte Incident-Response zu, anstatt sich ausschließlich auf monatliche Gebühren zu optimieren.
Der konträre Standpunkt: Warum Cloudflare-Aktien tatsächlich attraktiv erscheinen
Hier ist etwas, das Sie überraschen könnte: Trotz dieses katastrophalen Ausfalls würde ich argumentieren, dass Cloudflare-Aktien zum aktuellen Kurs von rund 196 US-Dollar, gegenüber dem Preis von 202 US-Dollar vor dem Ausfall, eine vernünftige Investition darstellen. Warum? Weil die Marktreaktion uns etwas Wichtiges darüber verrät, wie Anleger Infrastrukturrisiken bewerten.
Cloudflares Aktie fiel am 18. November um bis zu 7,0%, schloss jedoch nur mit einem Minus von 2,8%, nachdem das Unternehmen transparent kommuniziert und den Dienst schnell wiederhergestellt hatte. Diese relativ verhaltene Reaktion – verglichen mit Datenschutzverletzungen, die zu Rückgängen von 20-30% führen können – deutet darauf hin, dass Anleger dies als einen behebbaren operativen Vorfall und nicht als ein grundlegendes Unternehmensversagen betrachten.
Noch wichtiger ist, dass die zugrunde liegenden Finanzkennzahlen stark bleiben. Die Umsätze im Q3 2025 stiegen im Jahresvergleich um 31% auf 562 Millionen US-Dollar, während die Nettoverluste dramatisch von 15,3 Millionen auf nur 1,3 Millionen US-Dollar sanken, was eine klare Bewegung in Richtung Profitabilität zeigt. Da die Mehrheit der Analysten ihre „Kaufen“-Einstufungen beibehält, sagt der Markt im Wesentlichen: „Sie haben einen Fehler gemacht, sie haben ihn eingestanden, sie beheben ihn, und die langfristige Wachstumsgeschichte bleibt intakt.“
Für Führungskräfte enthält dies eine wertvolle Lektion über Krisenbewältigung: Transparenz, schnelle Abhilfemaßnahmen und konkrete Präventionsmaßnahmen können reputationsschäden begrenzen, selbst nach spektakulären operativen Fehlschlägen. Die Entscheidung von CEO Matthew Prince, innerhalb von 12 Stunden persönlich einen detaillierten technischen Postmortem-Bericht zu verfassen – einschließlich des fehlerhaften Codes – zeigte die Art von Verantwortungsbewusstsein, die Vertrauen schnell wiederherstellt.
Der Cloudflare-Ausfall vom 18. November 2025 war nicht nur ein technisches Versagen – er war ein Weckruf für die versteckte Architektur moderner Geschäftsabläufe. Wir haben unsere digitale Wirtschaft auf einer Grundlage konzentrierter Infrastruktur aufgebaut, die unter normalen Bedingungen bemerkenswerte Effizienz und Leistung liefert, aber bei Ausfällen systemische Risiken schafft.
Die Frage, der sich Führungskräfte gegenübersehen, ist nicht, ob ähnliche Ausfälle wieder auftreten werden – in Systemen dieser Komplexität und Skalierung sind sie unvermeidlich – sondern ob Ihr Unternehmen darauf vorbereitet sein wird. Die Unternehmen, die die nächste große Infrastrukturstörung am stärksten überstehen, werden diejenigen sein, die in strategische Redundanz investiert, unabhängige Überwachung beibehalten, ihre Backup-Prozeduren getestet und Infrastruktur-Resilienz als Anliegen auf Vorstandsebene behandelt haben, nicht als nachträglichen IT-Gedanken.
Wie ein Reddit-Nutzer während des Ausfalls treffend bemerkte, besteht das Internet immer noch aus „Klebeband und Gebeten“. Die Herausforderung für diese Generation von Führungskräften besteht darin, dieses Klebeband in geplante Resilienz zu verwandeln, während die Geschwindigkeit, Innovation und Zugänglichkeit erhalten bleiben, die das moderne Web so revolutionär gemacht haben. Die Kosten dieser Transformation werden in Millionen gemessen. Die Kosten, sie zu ignorieren, wie wir am 18. November gelernt haben, werden in Milliarden gemessen.