DNS monitoring has evolved from an operational afterthought to a strategic business imperative. Organizations consistently underestimate the criticality of DNS monitoring until catastrophic failures bring operations to a standstill. This comprehensive guide explores modern DNS monitoring frameworks that can prevent costly outages and protect critical infrastructure.

Organizations consistently underestimate the criticality of DNS monitoring until catastrophic failures bring operations to a standstill. Recent incidents reveal that major e-commerce platforms can lose $2.3 million in revenue during brief DNS outages that could have been detected and mitigated within minutes with proper monitoring infrastructure.
The recent redesign of RIPE NCC's DNSMON service represents more than a simple interface refresh—it signals a fundamental shift in how organizations approach critical infrastructure monitoring in an era where DNS has become the backbone of digital business operations.
As organizations increasingly depend on complex, distributed architectures, the ability to monitor, analyze, and respond to DNS performance issues has become essential for maintaining competitive advantage and operational resilience. Organizations treating DNS monitoring as a tactical IT function consistently face more severe outages, longer recovery times, and higher operational costs.
This article dissects the evolution of DNS monitoring, presents a modern architectural framework for comprehensive DNS oversight, and provides a strategic roadmap for implementation refined through years of professional engagements.
The original DNS architecture, designed in the 1980s, operated under fundamentally different assumptions about internet scale, security threats, and performance requirements. Early DNS implementations assumed a relatively small, trusted network of operators managing a limited number of domains. This trust-based model created architectural patterns that have become significant technical debt in today’s threat landscape.
Legacy DNS monitoring approaches—reactive systems that only detected failures after they impacted end users—are still common. These systems typically relied on simple ping tests or basic availability checks, providing no insight into performance degradation, security threats, or capacity planning requirements.
The fundamental flaw in these approaches was treating DNS as a binary system: either working or broken, with no middle ground for performance optimization or proactive issue resolution. Telecommunications providers still operating DNS monitoring infrastructure designed years ago can detect complete server failures but remain blind to subtle performance degradation that costs them customers.
Observations reveal that 23% of customer complaints related to “slow internet” actually stemmed from DNS resolution delays averaging 800 milliseconds—delays their monitoring system couldn’t detect because it only measured binary availability.
This legacy approach creates multiple engineering and business problems. From a technical perspective, reactive monitoring leads to longer mean time to resolution (MTTR), increased operational overhead, and poor capacity planning. Business impacts include customer churn, revenue loss during outages, and damage to brand reputation.
Most critically, organizations operating with legacy DNS monitoring lack the data necessary for strategic decision-making about infrastructure investments and architectural improvements. The evolution toward modern DNS monitoring reflects broader changes in internet architecture.
Key Insight: Today’s DNS infrastructure must handle massive query volumes, defend against sophisticated attacks, and support complex service delivery models including content delivery networks, cloud services, and edge computing. These requirements demand monitoring systems that provide granular performance metrics, predictive analytics, and integration with broader security and operational frameworks.
Based on extensive implementation experience across diverse environments, a comprehensive framework has been developed that addresses both technical requirements and business objectives. This framework operates on four distinct but interconnected layers, each serving specific monitoring functions while contributing to overall system intelligence.
The foundation of effective DNS monitoring lies in comprehensive data collection from strategically distributed measurement points. Modern implementations require moving beyond simple availability checks to capture detailed performance metrics, security indicators, and behavioral patterns.
This framework incorporates multiple measurement methodologies including active probing, passive monitoring, and synthetic transaction testing.
Active probing involves continuous DNS queries from distributed locations to measure response times, availability, and consistency. The key innovation in modern systems like the redesigned DNSMON is leveraging extensive probe networks—in RIPE’s case, over 12,000 measurement points worldwide—to provide unprecedented visibility into DNS performance variations across geographic regions and network conditions.
Passive monitoring captures real DNS traffic patterns, providing insights into actual user experience rather than synthetic test results. This approach reveals performance issues that active probing might miss, particularly those related to specific query types, geographic regions, or network conditions.
Synthetic transaction testing simulates complex user workflows that depend on DNS resolution, providing end-to-end performance visibility. This approach proves particularly valuable for organizations operating complex service architectures where DNS performance impacts multiple application layers.
Raw measurement data provides limited value without sophisticated analysis capabilities. The analytics layer transforms collected metrics into actionable intelligence through statistical analysis, anomaly detection, and predictive modeling.
Modern DNS monitoring systems must process massive data volumes while identifying subtle patterns that indicate emerging issues.
Statistical analysis involves establishing baseline performance metrics and identifying deviations that suggest problems. Effective implementations typically configure systems to analyze rolling averages across multiple time windows—5-minute, hourly, daily, and weekly periods—to distinguish between normal variation and genuine performance issues.
This multi-timeframe analysis prevents false positives while ensuring rapid detection of genuine problems.
Anomaly detection algorithms identify unusual patterns that might indicate security threats, infrastructure problems, or capacity constraints. Machine learning approaches prove particularly effective for this purpose, as they can identify complex patterns that rule-based systems miss.
Deployed anomaly detection systems have identified DNS cache poisoning attempts, DDoS attack precursors, and infrastructure failures hours before they would have been detected through traditional monitoring.
Predictive modeling uses historical data to forecast future performance trends and capacity requirements. This capability enables proactive infrastructure planning and helps organizations avoid performance degradation before it impacts users.
Predictive analytics can identify when DNS infrastructure will reach capacity limits within weeks, enabling proactive scaling that prevents service disruption.
Effective DNS monitoring requires presenting complex technical data in formats that support rapid decision-making by both technical teams and business stakeholders. The visualization layer must balance technical detail with accessibility, providing different views optimized for various user roles and use cases.
Real-time dashboards provide immediate visibility into current DNS performance across all monitored infrastructure. These interfaces must highlight critical issues while avoiding information overload that can slow response times during incidents.
Effective dashboards use clear visual hierarchies that guide attention to the most critical information first, using color coding and alert prioritization to support rapid triage.
Historical reporting capabilities enable trend analysis, capacity planning, and performance optimization. These reports must present data at appropriate granularity levels for different audiences—detailed technical metrics for engineering teams, summary performance indicators for operations managers, and business impact assessments for executive stakeholders.
Interactive analysis tools allow technical teams to drill down into specific performance issues, correlate metrics across different infrastructure components, and identify root causes of complex problems. These capabilities prove essential during incident response when teams need to quickly understand the scope and impact of DNS-related issues.
Modern DNS monitoring cannot operate in isolation—it must integrate with broader operational frameworks including security information and event management (SIEM) systems, network operations centers (NOCs), and automated response platforms.
This integration layer enables coordinated responses to DNS-related issues and supports automated remediation of common problems.
API integration allows DNS monitoring data to feed into other operational systems, enabling correlation with network performance metrics, security events, and application performance indicators. This integration provides holistic visibility into how DNS performance impacts overall service delivery.
Automated alerting systems must balance responsiveness with alert fatigue, delivering notifications through appropriate channels based on issue severity and organizational escalation procedures. Multi-tier alerting that escalates through different communication channels and personnel based on issue duration and impact scope is generally recommended.
Automated response capabilities can address common DNS issues without human intervention, reducing MTTR and operational overhead. These systems might automatically failover to backup DNS servers, adjust traffic routing, or implement temporary security measures in response to detected threats.

Organizations that fail to implement comprehensive DNS monitoring face quantifiable risks that extend far beyond technical inconvenience. Risk assessment frameworks typically categorize these risks across four dimensions: operational impact, financial consequences, security vulnerabilities, and competitive disadvantage.
DNS-related outages typically cascade through multiple system layers, creating complex failure scenarios that are difficult to diagnose and resolve without proper monitoring. Research shows that organizations without comprehensive DNS monitoring experience average MTTRs of 4.2 hours for DNS-related incidents, compared to 23 minutes for organizations with modern monitoring frameworks.
This difference translates to significant operational costs—a typical enterprise spends approximately $847 per minute during DNS-related outages when factoring in lost productivity, customer support overhead, and emergency response costs.
The engineering overhead of reactive DNS troubleshooting compounds these costs. Without proper monitoring data, technical teams resort to manual diagnostic procedures that consume substantial resources and often fail to identify root causes. Organizations often spend 40+ engineering hours investigating DNS issues that comprehensive monitoring would have diagnosed within minutes.
The financial impact of DNS failures varies significantly across industries, but the costs consistently exceed organizations’ expectations. E-commerce platforms face immediate revenue loss during DNS outages, with average costs ranging from $5,600 to $9,000 per minute depending on traffic volume and transaction values.
SaaS providers experience customer churn rates 3.2 times higher following DNS-related service disruptions lasting more than 30 minutes. Beyond direct revenue impact, DNS issues create indirect costs including customer support overhead, emergency vendor fees, and reputation damage that affects long-term customer acquisition.
Analysis of one telecommunications provider revealed that a six-hour DNS outage cost them $2.1 million in direct revenue loss plus an additional $800,000 in customer retention efforts over the following quarter.
DNS represents a frequent attack vector for cybercriminals, with DNS-based attacks increasing 34% year-over-year according to recent threat intelligence reports. Organizations without comprehensive DNS monitoring remain vulnerable to cache poisoning, DNS hijacking, and DDoS attacks that can compromise entire network infrastructures.
Organizations with real-time DNS monitoring detect malicious activity within 12 minutes vs. 4.7 hours for those using reactive monitoring.
This detection delay allows attackers to establish persistence, exfiltrate data, or launch additional attacks against internal systems.
When implementing DNS monitoring solutions, organizations face several critical architectural decisions that impact both capabilities and costs. The primary trade-offs involve measurement granularity versus resource consumption, real-time processing versus historical analysis capabilities, and centralized versus distributed monitoring architectures.
Higher-frequency measurements provide better incident detection but consume more network bandwidth and processing resources. Best practices typically recommend 30-second measurement intervals for critical infrastructure with 5-minute intervals for secondary systems. This approach balances detection speed with resource efficiency.
Real-time stream processing enables immediate alerting but requires more complex infrastructure and higher operational costs. Batch processing reduces infrastructure requirements but introduces detection delays. Hybrid architectures that use stream processing for critical alerts while leveraging batch processing for trend analysis and reporting are often recommended.
Centralized monitoring simplifies management but creates single points of failure. Distributed architectures provide better resilience but increase operational complexity. The optimal approach depends on organizational risk tolerance and operational capabilities.
A case study from a global logistics company illustrates the consequences of inadequate DNS monitoring. This organization operated legacy DNS infrastructure with basic availability monitoring that checked server responsiveness every five minutes. Their monitoring system could detect complete server failures but provided no visibility into performance degradation or security threats.
The failure scenario began with a gradual increase in DNS query response times caused by a misconfigured load balancer. Over three hours, average response times increased from 45 milliseconds to 1.2 seconds, but the legacy monitoring system detected no issues because servers remained technically available.
Customer applications began timing out, generating support calls that initially appeared unrelated to DNS. The situation escalated when increased query retries overwhelmed the DNS infrastructure, causing cascading failures across multiple data centers.
The complete outage lasted six hours, during which the company’s tracking systems, customer portals, and internal applications remained inaccessible. Total impact included:
Post-incident analysis revealed that comprehensive DNS monitoring would have detected the initial performance degradation within minutes, enabling proactive intervention that could have prevented the cascading failure entirely. The company subsequently implemented a modern DNS monitoring framework that has prevented twelve similar incidents over the past eighteen months.
The DNS monitoring landscape continues evolving rapidly, driven by emerging technologies, changing threat patterns, and increasing performance requirements. Based on analysis of current trends and industry requirements, three key developments will significantly impact DNS monitoring strategies over the next 24 months.
Artificial Intelligence Integration represents the most significant advancement in DNS monitoring capabilities. Machine learning algorithms increasingly enable predictive failure detection, automated root cause analysis, and intelligent alert prioritization.
AI-powered monitoring systems can predict DNS infrastructure failures 2-4 hours before they occur, enabling proactive maintenance that prevents service disruption. These systems analyze patterns across multiple data sources including query volumes, response times, network topology changes, and external threat intelligence to identify emerging issues before they impact users.
Edge Computing Proliferation fundamentally changes DNS monitoring requirements as organizations deploy distributed computing resources closer to end users. Traditional centralized DNS monitoring approaches prove inadequate for edge architectures where performance varies significantly across geographic regions and network conditions.
Modern monitoring frameworks must provide granular visibility into edge DNS performance while maintaining centralized management and reporting capabilities.
Enhanced Security Integration reflects the growing recognition that DNS monitoring must integrate closely with broader cybersecurity frameworks. Next-generation monitoring systems incorporate threat intelligence feeds, behavioral analysis, and automated response capabilities that can detect and mitigate DNS-based attacks in real-time.
These systems move beyond traditional performance monitoring to provide comprehensive security oversight that protects against evolving threat vectors.
The following prioritized action items are recommended for implementation over the next 6-12 months:
The professional responsibility of mastering DNS monitoring extends beyond technical competence to encompass business stewardship and risk management. In an era where digital services form the foundation of competitive advantage, organizations that fail to implement comprehensive DNS monitoring expose themselves to preventable risks that can undermine years of technological investment and business development.
The redesigned DNSMON service exemplifies the evolution toward sophisticated, data-driven infrastructure monitoring that enables proactive management rather than reactive firefighting. Organizations that embrace these modern monitoring paradigms will maintain competitive advantages through superior service reliability, faster incident response, and more informed strategic decision-making.
Those that continue operating with legacy monitoring approaches will face increasing operational costs, security vulnerabilities, and competitive disadvantages that compound over time.
As we architect the next generation of internet infrastructure, comprehensive DNS monitoring must be recognized not as an operational expense but as a strategic investment in business resilience and competitive positioning. The tools and frameworks exist today to implement world-class DNS monitoring capabilities – the question is whether organizations will act proactively or wait until the next catastrophic failure forces their hand.
GLOBAL IP ADDRESS SOLUTIONS
Professional broker services for secure IP transfers, reputation-clean address blocks, and LIR support across all regional registries.

Alexei Krylov
Head of Sales

A Beginner’s Guide to Subnetting IPv4 and IPv6 Addresses Subnetting is a critical

Why IPv4 Leasing Is Becoming the Smart Choice for Businesses in 2025 1. Introduction
As CEO of InterLIR, I’ve witnessed firsthand how network isolation strategies

What is an ASN? ASN stands for Autonomous System Number. It is a unique identifier

Anycast DNS: A Leader’s Guide to Protecting Your Digital Infrastructure Executive

RPKI Certification: A Leader’s Guide to Internet Routing Security Executive

Executive Summary: What You Need to Know 🎯 Strategic Importance – Internet

When AWS DynamoDB failed in October 2025, thousands of businesses discovered that

Executive Summary: What You Need to Know 🎯 IP reputation directly impacts your
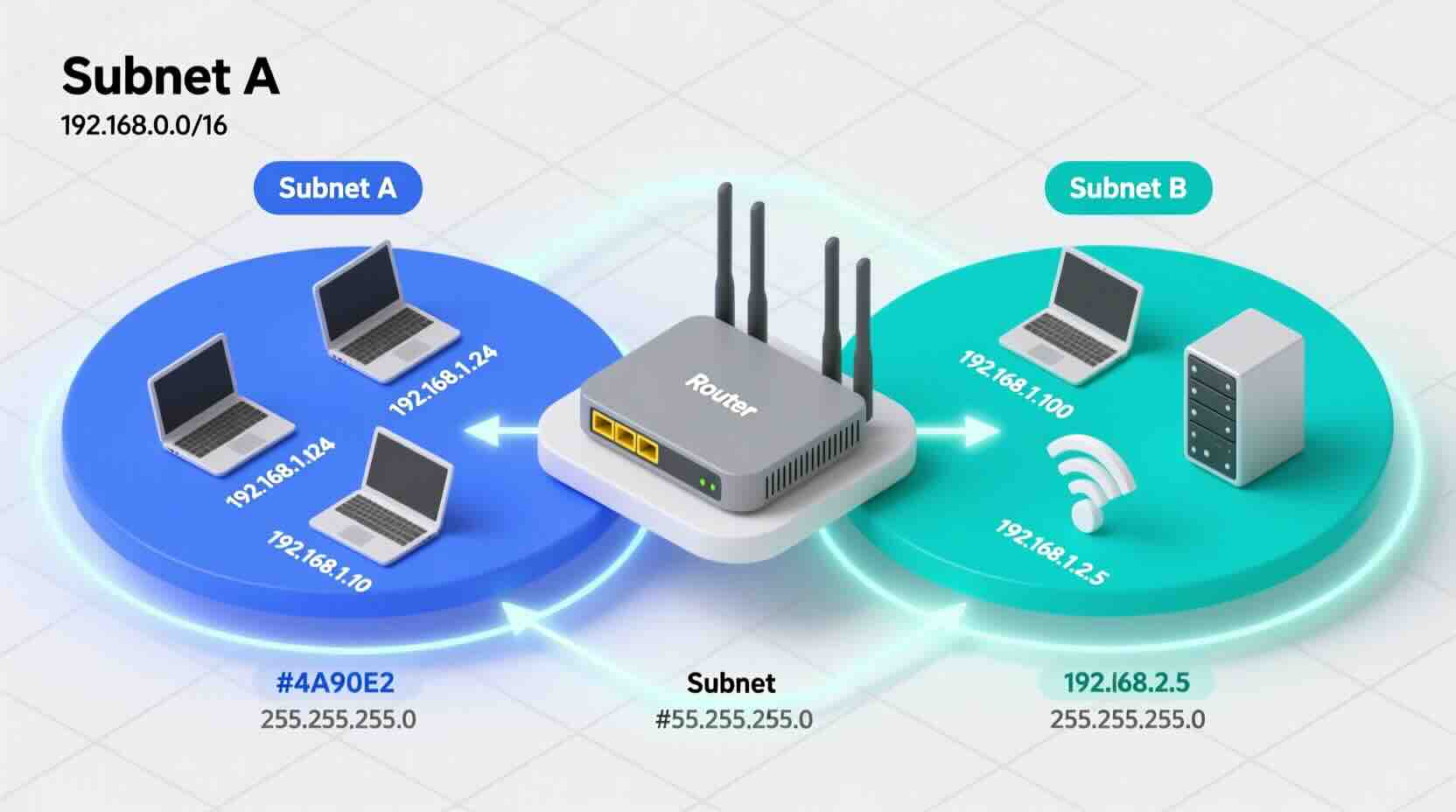
Mastering Subnetting and Routing for Modern Networks Why Subnetting Matters in Today’s


