🎯 Cloud-Service-Ausfälle sind Geschäftskontinuitätsereignisse – nicht nur technische Probleme. Der AWS DynamoDB-Vorfall zeigt, wie ein einzelnes technisches Versagen über mehrere Dienste hinweg kaskadieren und Geschäftsabläufe beeinträchtigen kann.
💰 Finanzielle Auswirkungen gehen über Ausfallzeiten hinaus – Unternehmen stehen vor Umsatzverlusten durch Transaktionsfehler, Kundenabwanderung aufgrund von Dienstunfähigkeit und Wiederherstellungskosten, die geplante IT-Budgets übersteigen können.
🚀 Multi-Region-Strategien sind unverzichtbar – Unternehmen, die regionsübergreifende Redundanz implementiert hatten, konnten ihren Betrieb während des AWS-Ausfalls aufrechterhalten, während solche, die von einer einzigen Region abhängig waren, erhebliche Störungen erlebten.
⚠️ Versteckte Abhängigkeiten schaffen unerwartete Schwachstellen – Die meisten Unternehmen sind sich der komplexen Wechselwirkungen zwischen Cloud-Diensten nicht bewusst, bis ein Ausfall sie offenlegt – oft zu spät, um die Auswirkungen zu mildern.
Stellen Sie sich vor, Sie kommen im Büro an und stellen fest, dass die E-Commerce-Plattform Ihres Unternehmens ausgefallen ist, sich Support-Tickets häufen und Ihr Team ein kritisches Sicherheits-Update nicht bereitstellen kann. Ihr CTO erklärt, dass dies auf eine „Race Condition im DNS von AWS DynamoDB zurückzuführen ist, die sich auf EC2- und NLB-Dienste ausgewirkt hat“. Für die meisten Führungskräfte klingt das nach technischem Jargon, der in die IT-Abteilung gehört. Aber sollte das so sein?
Einfach ausgedrückt: Störungen von Cloud-Diensten sind Geschäftskontinuitätsereignisse, die sich direkt auf Umsatz, Kundenzufriedenheit und Betriebsfähigkeit auswirken. Es handelt sich nicht nur um technische Probleme, sondern um geschäftliche Herausforderungen, die strategisches Verständnis und Aufmerksamkeit der Führungsebene erfordern.
Lassen Sie mich eine Perspektive aus meiner Erfahrung als Leiter von InterLIR, einem spezialisierten IPv4-Marktplatz, teilen. Wenn Cloud-Infrastrukturen ausfallen, ähnelt das den Herausforderungen, die Organisationen bei der Verfügbarkeit von IP-Adressen erleben. Beide Situationen haben unmittelbare geschäftliche Auswirkungen: Dienste werden unerreichbar, Transaktionen scheitern, und die Kundenerfahrung leidet. Die technischen Details sind weniger wichtig als das Verständnis der geschäftlichen Konsequenzen und Strategien zur Aufrechterhaltung des Betriebs.
Die AWS-Service-Störung im Oktober 2025 ist ein perfektes Fallbeispiel. Was als scheinbar obskures technisches Problem begann – eine Race Condition im DNS-Management-System von DynamoDB – entwickelte sich zu einer 15-stündigen Unterbrechung, die Tausende von Unternehmen über mehrere Dienste hinweg betraf. Unternehmen ohne geeignete Resilienzstrategien sahen sich erheblichen betrieblichen und finanziellen Folgen gegenüber.
In diesem Leitfaden werde ich erläutern, was Cloud-Service-Ausfälle in geschäftlicher Hinsicht bedeuten, warum das Verständnis ihrer Funktionsweise für die strategische Planung entscheidend ist, und einen klaren Rahmen für fundierte Entscheidungen zur Cloud-Resilienz bieten. Sie müssen kein technischer Experte werden, aber Sie müssen genug verstehen, um die richtigen Fragen zu stellen und Ressourcen angemessen zuzuteilen.
Traditionelle IT-Ausfälle betreffen typischerweise ein einzelnes System oder einen Standort. Wenn der E-Mail-Server Ihres Unternehmens in der Vergangenheit ausfiel, war dies ein isolierter Vorfall mit klaren Grenzen. Cloud-Service-Ausfälle sind grundlegend anders – sie ähneln eher einer komplexen Kettenreaktion, die sich unvorhersehbar durch vernetzte Systeme ausbreitet.
In den Anfängen der Datenverarbeitung war die Infrastruktur relativ einfach. Jedes Unternehmen unterhielt seine eigenen Server in einem dedizierten Rechenzentrum. Wenn etwas ausfiel, war die Auswirkung begrenzt und der Lösungsweg klar: die defekte Komponente reparieren oder ersetzen. Als Führungskraft konnten Sie Ihre Infrastruktur sehen und anfassen, was die Risiken greifbar und leichter einzuschätzen machte.
Mit der Weiterentwicklung der Technologie hat sich dieses Modell stark verändert. Die heutige Cloud-Infrastruktur ähnelt eher einer riesigen, vernetzten Stadt als einer Ansammlung einzelner Gebäude. In dieser digitalen Metropole sind Dienstleistungen stark voneinander abhängig, was komplexe Ausfallmuster erzeugt, die sich auf unerwartete Weise ausbreiten können. Wenn ein kritischer Dienst ausfällt, kann dies eine Kettenreaktion von Ausfällen in scheinbar unabhängigen Systemen auslösen – ähnlich wie ein Stromausfall in einem Stadtteil den Verkehr, den Handel und die Kommunikation in der gesamten Stadt beeinträchtigen kann.
Der AWS-Vorfall veranschaulicht diese neue Realität. Lassen Sie uns analysieren, was in geschäftlicher Hinsicht passiert ist:
1️⃣ Der anfängliche Ausfall – Eine Race Condition im DNS-Management-System von DynamoDB führte dazu, dass der Dienst nicht mehr erreichbar war. Stellen Sie sich dies wie einen kritischen Ausfall des Hauptkraftwerks in unserer Stadtanalogie vor.
2️⃣ Der Kaskadeneffekt – Dieser anfängliche Ausfall löste Probleme in EC2 (Rechenleistung) und NLB (Netzwerk-Load-Balancer) aus, die von DynamoDB abhängig sind. In unserer Stadtanalogie ist dies wie ein Stromausfall, der Ampeln ausfallen lässt, was dann zu einem Verkehrschaos im gesamten Transportsystem führt.
3️⃣ Die Herausforderung der Wiederherstellung – Selbst nach der Behebung des anfänglichen DynamoDB-Problems blieben die sekundären Systeme aufgrund von Rückstau und Retry-Stürmen beeinträchtigt. Dies ähnelt dem Phänomen, dass Verkehrsstaus noch lange bestehen bleiben, nachdem Ampeln wieder funktionieren.
Was dies besonders herausfordernd macht, ist, dass die meisten Organisationen sich dieser Abhängigkeiten nicht bewusst waren, bis sie die Auswirkungen spürten. Viele Führungskräfte entdeckten kritische Schwachstellen in ihrer Cloud-Architektur erst, nachdem ihre Dienste bereits betroffen waren.
Cloud-Dienste arbeiten nach dem Prinzip der Abstraktion – sie verbergen Komplexität, um Systeme einfacher nutzbar zu machen. Während dies enorme Vorteile bietet, verschleiert es auch das komplexe Geflecht von Abhängigkeiten, die Ihr Geschäft beeinflussen können. Betrachten Sie diesen Vergleich:
| Traditioneller IT-Ausfall | Störung des Cloud-Dienstes | Geschäftliche Auswirkungen |
|---|---|---|
| Hardware-Ausfall des Servers | DNS-Wettlaufsituation, die kaskadierende Dienstausfälle auslöst | Was wie ein einfacher Komponentenausfall erscheint, kann mehrere Geschäftsfunktionen gleichzeitig beeinträchtigen |
| Netzwerkausfall in Ihrem Rechenzentrum | Regionsweite Dienstbeeinträchtigung | Das Ausmaß der Auswirkungen ist um Größenordnungen größer |
| Klare Verantwortung und Kontrolle über die Wiederherstellung | Abhängigkeit von den Wiederherstellungsprozessen des Cloud-Anbieters | Begrenzte Möglichkeit, die Lösungszeiträume direkt zu beeinflussen |
| Vorhersehbare Auswirkungen auf bestimmte Systeme | Unvorhersehbare Ausbreitung über Dienste hinweg | Schwierigkeiten bei der Bewertung der gesamten geschäftlichen Auswirkungen während eines Vorfalls |
Dieser grundlegende Unterschied erfordert einen neuen Ansatz für die Business-Continuity-Planung. Der AWS-Vorfall zeigt, dass Entscheidungen zur technischen Architektur direkte geschäftliche Auswirkungen haben, die weit über die IT-Abteilung hinausgehen. Diese Auswirkungen zu verstehen, ist jetzt eine zentrale Verantwortung der Unternehmensführung.
Wenn Cloud-Dienste ausfallen, gehen die Auswirkungen weit über technische Kennzahlen wie „Systemausfallzeit“ oder „Fehlerraten“ hinaus. Sie wirken sich unmittelbar auf geschäftliche Konsequenzen aus, die Umsatz, Kundenerlebnis, Betriebsfähigkeit und sogar regulatorische Compliance betreffen. Lassen Sie uns diese Auswirkungen anhand des AWS-Vorfalls untersuchen.

Während der AWS-Störung verzeichneten Unternehmen mehrere direkte Umsatzauswirkungen:
💸 Transaktionsfehler – E-Commerce-Plattformen, die für Bestands- oder Zahlungsabwicklungen auf DynamoDB angewiesen sind, verzeichneten fehlgeschlagene Transaktionen. Ein Einzelhandelskunde meldete Verluste von etwa 150.000 US-Dollar an Umsatz während eines vierstündigen Zeitraums, in dem der Bezahlvorgang nicht verfügbar war.
🔄 Störungen im Abonnementmanagement – SaaS-Unternehmen, die betroffene Dienste für das Abonnementmanagement nutzten, hatten Schwierigkeiten bei der Abwicklung neuer Abonnements und Verlängerungen, was zu Einnahmeausfällen führte.
📉 Unwirksamkeit von Marketingkampagnen – Unternehmen, die zeitkritische Aktionen durchführten, sahen ihre Kampagnen untergraben, da Kunden keine Käufe abschließen konnten, was Marketingbudgets und Chancen verschwendete.
Besonders bemerkenswert ist, wie diese Auswirkungen je nach Architekturentwürfen variierten. Unternehmen, die Multi-Region-Strategien implementiert hatten, behielten zumindest teilweise Funktionalität bei, während jene, die von einer einzelnen Region abhängig waren, vollständige Ausfälle erlebten. Dies zeigt, wie technische Architekturentscheidungen direkt die Geschäftsresilienz und den Umsatzschutz beeinflussen.
Neben den direkten Umsatzauswirkungen beeinträchtigte die Störung die Fähigkeit der Organisationen, effektiv zu arbeiten:
🚫 Bereitstellungsstopps – Organisationen konnten keine neuen EC2-Instanzen starten, was sie zwang, geplante Softwareveröffentlichungen und Infrastruktur-Skalierungen zu verschieben. Ein Finanzdienstleistungsunternehmen musste die Bereitstellung eines kritischen Sicherheitsupdates um 24 Stunden verschieben.
🔍 Überwachungsausfälle – Viele Unternehmen verloren die Sichtbarkeit ihrer Systeme, als Überwachungstools, die von betroffenen Diensten abhingen, nicht mehr funktionierten. Dies beeinträchtigte ihre Fähigkeit, die Auswirkungen zu bewerten und effektiv zu reagieren.
🧯 Einschränkungen bei der Incident-Response – Technische Teams konnten keine Standardmaßnahmen zur Problembehebung durchführen, die das Starten neuer Ressourcen oder den Zugriff auf betroffene Dienste erforderten.
Diese betrieblichen Auswirkungen hatten oft sekundäre Geschäftskonsequenzen, die weit über die technische Störung hinausgingen. Beispielsweise führte die oben erwähnte verzögerte Bereitstellung des Sicherheitsupdates zu Compliance-Problemen, die eine Meldung an Aufsichtsbehörden erforderlich machten.
Die vielleicht gravierendsten geschäftlichen Auswirkungen ergaben sich durch die Verschlechterung der Kundenerfahrung:
😠 Erhöhtes Supportaufkommen – Unternehmen berichteten von einer Zunahme der Support-Ticket-Volumen um 300-500% während der Störung, was die Support-Teams überforderte und zusätzliche betriebliche Herausforderungen schuf.
🔁 Wiederholte Fehlererfahrungen – Kunden, die versuchten, die Dienste zu nutzen, sahen sich mit frustrierenden Fehlermeldungen oder endlosen Ladeanzeigen konfrontiert, was negative Markenassoziationen erzeugte.
💔 Vertrauensverlust – Bei Diensten, bei denen Zuverlässigkeit ein zentrales Wertversprechen ist (Finanzdienstleistungen, Gesundheitswesen, kritische Geschäftstools), schädigte die Störung die Markenwahrnehmung und das Vertrauen.
Die Auswirkungen auf das Kundenerlebnis dauerten oft länger als die technische Störung selbst. In unserer Arbeit bei InterLIR haben wir beobachtet, dass das Kundenvertrauen etwa 2-3 Mal länger braucht, um sich wiederherzustellen, als der eigentliche Dienst. Dies schafft eine „Vertrauensschuld“, die Unternehmen durch konsequente Zuverlässigkeit nach einem Vorfall zurückzahlen müssen.
Bei der Berechnung der tatsächlichen geschäftlichen Kosten von Cloud-Störungen müssen Führungskräfte mehrere Faktoren berücksichtigen:
| Kostenkategorie | Beispiele | Berechnungsmethode |
|---|---|---|
| Direkter Umsatzverlust | Fehlgeschlagene Transaktionen, Abonnementunterbrechungen | Transaktionsvolumen × Durchschnittswert × Ausfallprozentsatz |
| Betriebskosten | Überstunden, Notfallmaßnahmen, Wiederherstellungsaufwand | Zusätzliche Arbeitsstunden × vollständige Kostenbelastung |
| Kundenauswirkungen | Supportanstieg, Rufschädigung, Kundenabwanderung | Supportvolumensteigerung × Bearbeitungskosten + geschätzter Abwanderungswert |
| Opportunitätskosten | Verzögerte Einführungen, Wettbewerbsnachteile | Geschätzter Wert verzögerter Initiativen |
| Compliance-Folgen | Regulatorische Meldungen, potenzielle Strafen | Direkte Kosten + risikobereinigte potenzielle Strafen |
Diese umfassende Betrachtung der Geschäftsauswirkungen sollte sowohl die Prioritäten während der Wiederherstellung eines Vorfalls als auch die Investitionsentscheidungen für Resilienzstrategien leiten. Die Organisationen, die die AWS-Störung am effektivsten bewältigten, waren jene, die diese Analyse zuvor durchgeführt und entsprechend investiert hatten.
Die Schaffung von Cloud-Resilienz besteht nicht nur darin, die robustesten technischen Lösungen zu implementieren – es geht um strategische Investitionen, die auf Geschäftsprioritäten basieren. Der AWS-Vorfall liefert wertvolle Einblicke in effektive Ansätze, die Kosten und Schutz in Einklang bringen.
Cloud-Resilienz existiert auf einem Spektrum, wobei unterschiedliche Ansätze verschiedene Schutzgrade zu unterschiedlichen Kosten bieten:
🔹 Grundlegende Resilienz – Dieser Ansatz konzentriert sich auf die Wiederherstellung anstatt auf Kontinuität, akzeptiert gewisse Ausfallzeiten, stellt jedoch sicher, dass Daten geschützt und Dienste wiederhergestellt werden können. Dies ist für nicht-kritische Geschäftsfunktionen geeignet.
🔶 Erweiterte Resilienz – Implementiert Redundanz innerhalb einer Region und grundlegende regionsübergreifende Fähigkeiten für die kritischsten Komponenten. Dieser Ansatz kann die Kernfunktionalität bei vielen Arten von Störungen aufrechterhalten.
🔷 Fortgeschrittene Resilienz – Nutzt aktive-aktive Multi-Region-Architekturen mit automatischem Failover. Dieser Ansatz gewährleistet nahezu kontinuierlichen Betrieb, jedoch mit deutlich höheren Kosten und Komplexität.
Während des AWS-Vorfalls erlebten Organisationen in diesem Spektrum dramatisch unterschiedliche Ergebnisse. Unternehmen mit grundlegender Resilienz sahen sich mit vollständigen Ausfällen konfrontiert, während solche mit fortgeschrittener Resilienz ihren Betrieb mit minimalen Auswirkungen aufrechterhalten konnten. Jedoch ist die zentrale Erkenntnis, dass gezielte Resilienz – die Anwendung des richtigen Schutzniveaus für jede Geschäftsfunktion basierend auf deren Kritikalität – die beste Rendite erzielte.
Basierend auf dem AWS-Vorfall und unseren Erfahrungen bei InterLIR mit Organisationen, die kritische Netzwerkressourcen verwalten, empfehle ich diese strategischen Ansätze:
1️⃣ Priorisierung von Geschäftsfunktionen – Kategorisieren Sie Ihre Geschäftsfunktionen nach Kritikalität, unter Berücksichtigung von Umsatzauswirkungen und Kundenerfahrung. Dies schafft einen klaren Rahmen für Investitionsentscheidungen zur Resilienz.
2️⃣ Abhängigkeitsabbildung – Identifizieren Sie die vollständige Kette der Cloud-Service-Abhängigkeiten für jede kritische Geschäftsfunktion. Der AWS-Vorfall zeigte, wie versteckte Abhängigkeiten Resilienzstrategien untergraben können.
3️⃣ Zielgerichtete Multi-Region-Implementierung – Wenden Sie Multi-Region-Architekturen zuerst auf Ihre kritischsten Funktionen an. Während des AWS-Vorfalls bot sogar eine teilweise Multi-Region-Implementierung erheblichen Schutz.
4️⃣ Design für elegante Degradation – Entwickeln Sie Systeme so, dass sie die Kernfunktionalität auch bei Ausfall einiger Komponenten aufrechterhalten. Dieser Ansatz bot erheblichen Geschäftsschutz zu moderaten Kosten.
5️⃣ Regelmäßige Resilienztests – Validieren Sie Ihre Resilienzstrategien durch kontrollierte Tests. Organisationen, die zuvor Regionenausfall-Szenarien getestet hatten, reagierten während des tatsächlichen Vorfalls effektiver.
Dieser strategische Ansatz ermöglicht es Organisationen, eine bedeutende Resilienz zu erreichen, ohne die prohibitiv hohen Kosten für die Implementierung erweiterter Schutzmaßnahmen für alle Systeme. Es geht darum, intelligente Investitionen auf der Grundlage von Geschäftsprioritäten zu tätigen.
Mehrere spezifische technische Muster erwiesen sich während des AWS-Vorfalls als besonders effektiv, während sie gleichzeitig ein angemessenes Kostenprofil beibehielten:
💡 Lese-Replikate über Regionen hinweg – Organisationen, die schreibgeschützte Daten über Regionen hinweg replizierten, behielten die Fähigkeit, Informationen abzurufen, auch wenn Schreiboperationen beeinträchtigt waren. Dieses Muster ist deutlich kostengünstiger als vollständige Active-Active-Implementierungen, bewahrt aber gleichzeitig kritische Fähigkeiten.
💡 Statische Fallback-Lösungen – Dienste, die statische Fallback-Inhalte implementierten, hielten während der Störung grundlegende Kundenerlebnisse aufrecht. Dieses einfache Muster bot erheblichen Markenschutz zu minimalen Kosten.
💡 Circuit Breaker und Bulkheads – Systeme, die dafür ausgelegt sind, Ausfälle zu isolieren, verhinderten den Kaskadeneffekt, der die AWS-Störung verstärkte. Diese architektonischen Muster verursachen nur geringe Kosten, verbessern aber die Resilienz erheblich.
💡 Asynchrone Verarbeitung – Organisationen, die Systeme für die spätere Verarbeitung von Operationen in Warteschlangen entwarfen, behielten während der Störung die Funktionalität bei und erholten sich danach schneller.
Besonders bemerkenswert an diesen Mustern ist, dass sie keine vollständige Duplizierung der Infrastruktur über Regionen hinweg erfordern. Stattdessen konzentrieren sie sich darauf, kritische Fähigkeiten durch gezielte Resilienzstrategien aufrechtzuerhalten. Dieser Ansatz bietet erheblichen Geschäftsschutz zu einem Bruchteil der Kosten einer vollständigen Redundanz.
Als Führungskraft müssen Sie nicht jedes technische Detail der Cloud-Architektur verstehen, aber Sie müssen die richtigen Fragen stellen, um sicherzustellen, dass Ihr Unternehmen angemessen geschützt ist. Der AWS-Vorfall verdeutlicht mehrere kritische Fragestellungen, die

Alexander Timokhin
CEO
Die Erschöpfung der IPv4-Adressen ist ein dringendes Problem, und Unternehmen erkennen
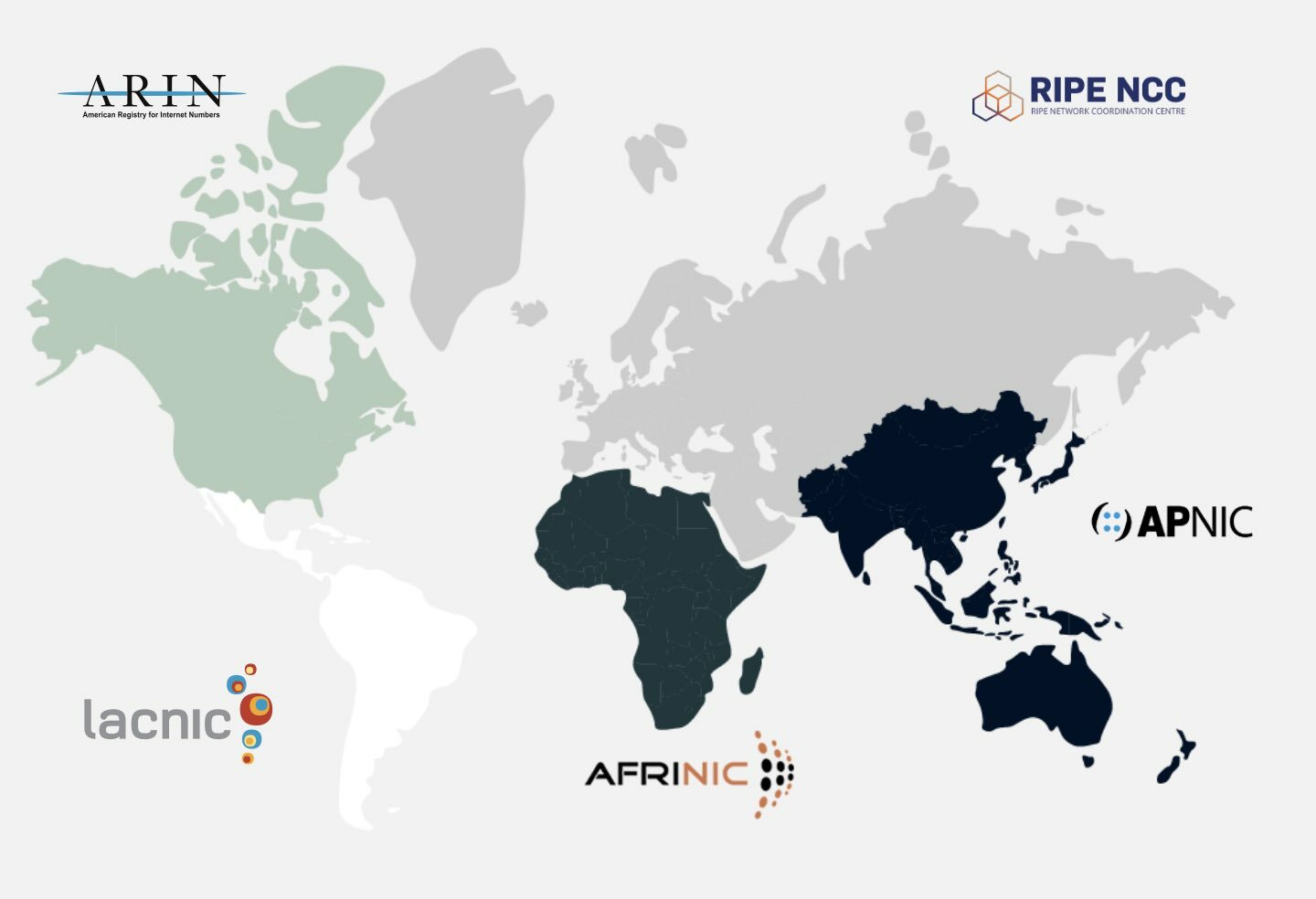
Die große Umverteilung des IP-Adressraums: Warum die IPv4-„Knappheit“
InterLIR GmbH ist eine Marktplatzlösung, die sich zum Ziel gesetzt hat, Netzwerkverfügbarkeitsprobleme
Auch wenn Sie nicht vorhaben, Ihr IPv4-Netzwerk zu verkaufen, gibt es immer noch
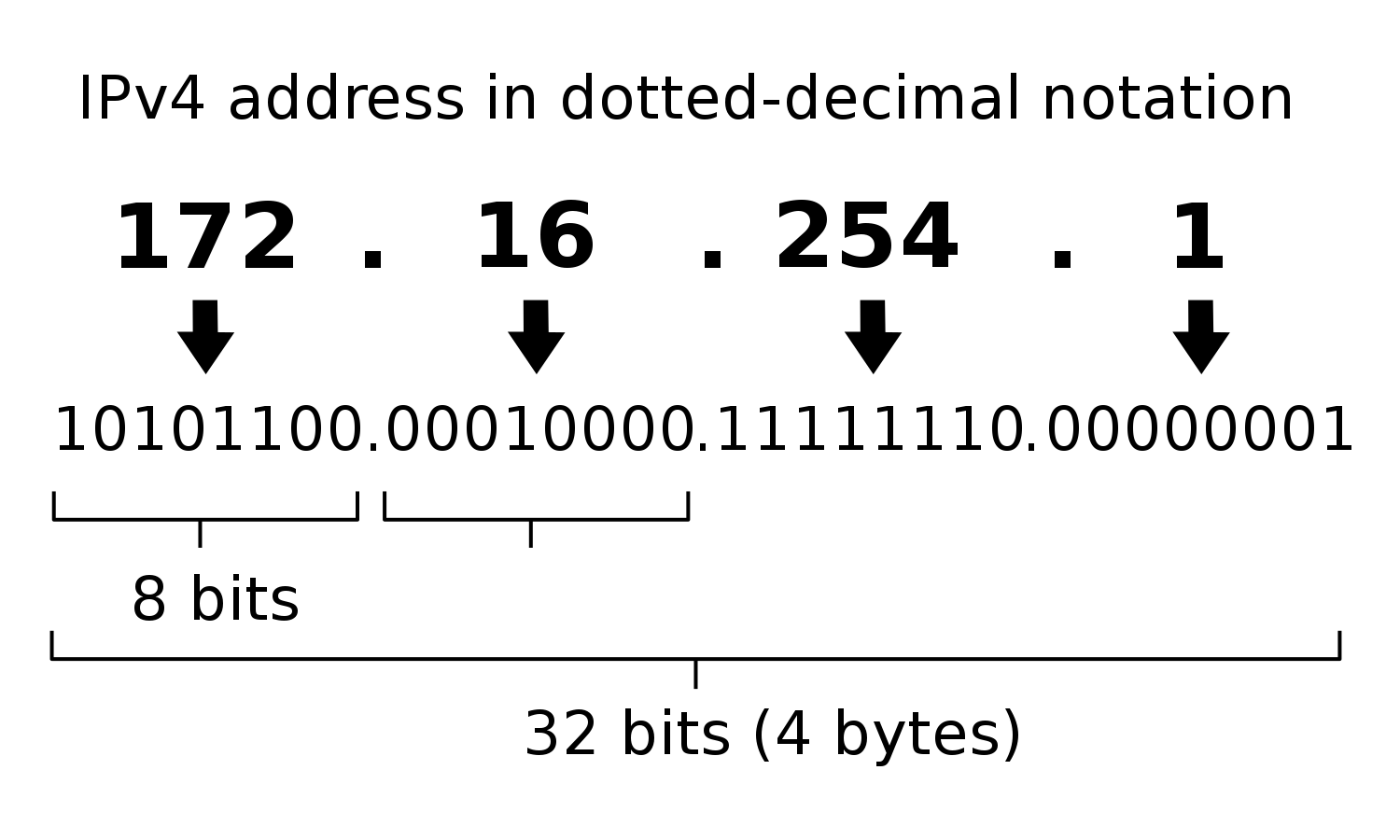
Eine Internet Protocol (IP)-Adresse ist eine eindeutige Kennung, die jedem mit dem
Die steigende Nachfrage nach IP-Blöcken hat die Preise in die Höhe getrieben und
Netzwerk-IP-Adressen variieren und erfordern eine fachkundige Beratung für Netzwerkbetreiber.
Einführung Im heutigen digitalen Umfeld ist der Schutz der Netzwerksicherheit von
In einer Ära, die von digitaler Konnektivität vorangetrieben wird, hat der Wert