当20%的互联网陷入黑暗:商业领袖理解基础设施风险的指南
执行摘要:您需要了解的关键信息
🎯 关键基础设施集中化:2025年11月18日,Cloudflare一次持续六小时的技术故障导致全球20%的互联网流量中断,从AI聊天机器人到麦当劳点餐终端都受到影响——这暴露了我们对少数基础设施提供商的危险依赖。
💰 巨大的经济影响:此次中断每小时给所有受影响企业造成的总损失估计在50亿至150亿美元之间,单个企业每小时损失在30万至100万美元不等(取决于规模)。
🚀 需要采取战略行动:商业领袖必须立即审核其基础设施依赖关系,实施多供应商冗余策略,并为下一次重大中断(不是“是否”会发生,而是“何时”会发生)准备好“数字备用发电机”。
⚠️ 股市教训:尽管发生了灾难性的运营故障,Cloudflare的股价在收盘时仅下跌了2.8%,这表明当公司以透明度和具体的预防措施回应时,投资者将基础设施弹性视为可控风险。
非技术领袖为何要关心一次“技术性”中断?
让我从一个可能在2025年11月18日发生在您组织内的简单场景开始。您的营销团队无法访问Canva中的设计工具。您的客户服务平台陷入黑暗。您的开发人员无法使用ChatGPT或Claude来协助编码。您的员工无法预订休假时间,因为人力资源系统宕机。如果您经营零售店,您的自助服务终端可能显示错误页面,而不是接受订单。
所有这些故障——跨越完全不同的公司和平台——都有一个共同的根源:Cloudflare,这家处理约20%互联网流量的隐形基础设施公司,经历了一次持续近六小时的灾难性技术故障。 可以将Cloudflare视为现代互联网的电网。当电网崩溃时,无论您的建筑设计得多好,或者您在运营上投入了多少——灯就是打不开。
简单来说,像Cloudflare这样的云基础设施提供商是数字时代的公共事业——在故障前是隐形的,但对业务运营绝对至关重要。 它们决定了客户是否能访问您的网站,您的应用程序是否能正常运行,以及您的数字服务在关键营业时间内是否保持可访问。当它们宕机时,您的业务也随之宕机,无论您在自己的技术上投入了多少。
使这次事件成为一个分水岭时刻的,不仅是其规模(尽管影响数亿用户并造成数十亿美元损失确实算得上),更重要的是它揭示了现代业务运营中隐藏的架构风险。我们将如此多的数字基础设施集中在少数几家提供商周围,以至于它们的故障现在会同时波及整个经济领域。理解这种集中风险并为之做好准备不再是可选项——而是一项基本的业务连续性要求。
在本指南中,我将剖析2025年11月18日发生的事件,将技术复杂性转化为商业语言,解释这对您的战略规划为何重要,并提供清晰的路线图来保护您的组织在未来免受类似中断的影响。让我们从了解我们如何陷入这种岌岌可危的境地开始。
我们为何变得如此依赖少数几家基础设施公司?
要理解今天基础设施的脆弱性,我需要带您回到20世纪90年代商业互联网的早期。想象一下互联网是一个小镇,每家企业都运行自己的服务器,管理自己的安全,并处理自己的流量路由。当只有数千个网站时,这种方法运作良好,但它需要大多数企业无法持续投入的深厚技术专长和大量资本投入。
从独立发电机到共享电网
随着互联网规模的爆炸式增长——从数千个网站到数十亿个——自然的整合发生了。像Cloudflare、亚马逊网络服务(AWS)和微软Azure这样的公司成为了数字时代的“电力公共事业公司”。 它们承诺处理所有复杂的基础设施工作——安全、速度优化、流量路由、DDoS防护——这样企业就可以专注于其核心竞争力,而不是管理服务器。
这种转变带来了巨大的好处。一家小型电子商务初创公司可以以一小部分的成本获得与财富500强公司相同等级的企业级基础设施。网站加载速度更快。安全性显著提高。启动数字业务的技术壁垒大大降低。可以将其想象成从每栋建筑都有自己的发电机,变成了所有人都连接到可靠的电网——这更高效、更具成本效益,而且通常更可靠。
然而,这种整合也创造了一种我们现在才充分认识到的新风险类别。当每个人都连接到同一个电网时,该电网的故障会同时影响到每个人。 二十年前,正如基础设施专家Mike Chapple所指出的,个别服务中断很常见——你可能一周内至少会有一项IT服务宕机。但每次中断只影响那一家公司。今天,我们通过整合实现了显著的聚合可靠性,但也创造了一种新风险:当这些基础设施巨头之一跌倒时,20%的互联网会同时瘫痪。
数字讲述了这种集中化的故事。仅Cloudflare一家在正常情况下每秒处理8100万个HTTP请求。大约35%的财富500强公司依赖其服务。全球访问量最大的10,000个网站中约有32%使用其基础设施。我们实际上将全球数字经济的重要组成部分放在了一个单一的平台上——这对效率来说是美妙的,但对弹性来说是可怕的。
2025年11月18日究竟发生了什么?
让我将这次技术故障转化为一个商业类比,以说明哪里出了问题。想象您经营一家全球物流公司,在全球拥有330个配送中心。每五分钟,您的总部会向所有中心发送更新的运输指令。这些指令通常大小可控——大约60页的指示。
变得过大的配置文件
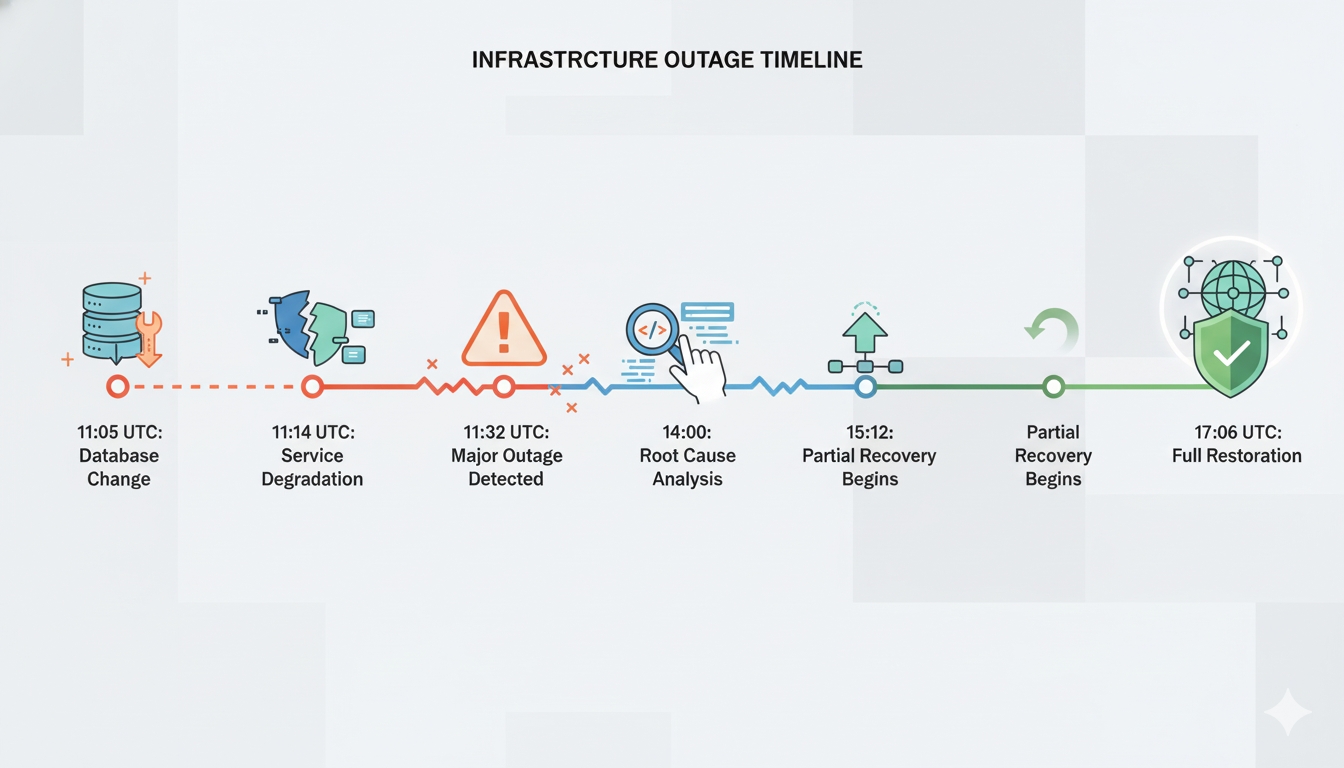
在11月18日上午,一项旨在改进数据库安全设置的善意更改无意中导致系统从两个来源而不是一个来源拉取运输数据。突然之间,这些指令文件的大小翻倍,超过了200页——超出了您的配送中心设计处理能力。 每个中心的系统试图加载这些过大的指令,超出了其内存容量,并完全崩溃。无法处理订单。无法发货。整个全球运营陷入停顿。
这基本上就是发生在Cloudflare身上的事情。UTC时间11:05,他们进行了一项旨在提高安全性的常规数据库权限更改——相当于升级您的门锁。这一更改引发了一个意想不到的后果:其Bot Management系统使用的配置文件开始拉取重复数据。文件大小从大约60个特性激增到200多个特性。这个过大的文件通过其快速部署系统在几秒钟内自动分发到全球330多个数据中心。
速度为何成了敌人
这就是现代基础设施的效率增益变成负债的地方。Cloudflare的部署系统可以在大约几秒钟内在全球范围内传播更改——这是一项令人印象深刻的工程成就,能够实现快速的安全响应。 但这同样的速度意味着错误也能在人类操作员干预之前瞬间传播到所有数据中心。当UTC时间11:31有人注意到问题(在首次出现错误后仅11分钟)时,有缺陷的配置已经多次传播到全球。
更增加了诊断复杂性的是,故障模式是间歇性的。服务会工作五分钟,然后故障五分钟,然后又工作。这种交替模式模仿了网络攻击的特征,导致事件响应团队最初调查了错误的原因。直到UTC时间14:24——中断开始后三个多小时——才确定了根本原因,并阻止了自动化系统生成过大的配置文件。
技术故障的人力成本
中断的范围远远超出了您对一个“技术性”问题的预期。像X(Twitter)、ChatGPT、Spotify、Discord、Zoom和Shopify这样的主要平台都同时下线。但真正令人震惊的影响发生在实体企业:麦当劳餐厅无法通过其终端点餐。托儿所无法通过电子系统签到或签出儿童。交通系统失去了实时信息显示。公司员工无法访问人力资源系统来申请休假。
甚至监控系统也失效了。DownDetector——人们用来检查其他网站是否宕机的网站——本身也下线了,因为它也依赖Cloudflare。这造成了一种超现实的情况:用户无法可靠地确认他们的问题是孤立的还是更大范围中断的一部分,这在社交媒体平台上引发了混乱和焦虑。
基础设施依赖的真实商业成本是什么?
当我与商业领袖讨论这一事件时,第一个问题总是:“这到底造成了多少损失?”答案揭示了为什么基础设施弹性必须是董事会层面的问题,而不仅仅是IT问题。
同时故障的隐藏乘数效应
关于停机成本的研究表明,93%的大型企业每小时停机成本超过30万美元,而48%的企业报告每小时成本超过100万美元。但这些数字反映的是单个公司的中断。当成千上万的公司同时下线时,经济影响不是简单的相加——而是成倍增长。
分析师估计,所有受影响企业的总经济损失为每小时50亿至150亿美元。在持续六小时的时间内,这转化为潜在的总损失在数亿到数十亿美元之间。让我分解一下这些成本累积的地方:
💸 直接收入损失:电子商务平台无法在跨越多个全球时区的购物高峰期处理交易——离线的每一分钟都代表着永远无法挽回的销售损失。
📉 营销浪费:正在运行活跃广告活动的公司继续为点击和展示付费,但这些点击和展示却导向错误页面而非正常网站——营销预算在零回报中被消耗。
🔥 品牌损害:研究表明,88%的用户在经历糟糕体验后不太可能再次访问某个网站,即使他们在理性上理解原因是第三方故障且公司无法控制。
⚖️ 合同罚金:与客户的服务水平协议(SLA)触发了罚金条款,并为错过的正常运行时间保证强制要求信用额度。
👥 生产力崩溃:全球数亿知识工作者无法访问基本工具,许多人在中断期间根本无法工作。
📞 支持成本激增:客户服务团队被用户咨询淹没,这些用户没有意识到问题是普遍性的,资源从正常运营中被转移。
外汇交易行业:详细案例研究
为了使其具体化,考虑一下对外汇和差价合约(CFD)经纪商的影响。这些平台在正常情况下每三小时促成约15.8亿美元的交易量。在Cloudflare中断期间,包括Monaxa、Skilling、Xtrade和FXPro在内的多家经纪商经历了完全的业务瘫痪。交易者无法访问他们的仓位,无法执行交易,也无法对市场波动做出反应。 那三个小时窗口内的全部交易量——大致相当于其典型月交易量的1%——直接蒸发了。
同样,加密货币交易所报告在中断高峰期交易量显著下降。NFT市场活动几乎萎缩至零。一些依赖Cloudflare进行API连接的区块链Layer 2网络变得完全无法访问,暴露了“去中心化”应用程序通常依赖中心化基础设施的讽刺现象。
为何“这不是我们的错”无法保护您的业务
作为一个顾问,这里有一个让我夜不能寐的不安事实:客户不关心中断是谁的错——他们只关心在需要时您的服务没有工作。 当您的网站显示Cloudflare错误页面而不是正常加载时,您的品牌会遭受声誉打击,即使技术故障发生在您无法控制的基础设施中。
这就是为什么将基础设施提供商视为“别人的问题”是一个战略错误。它们的可靠性直接影响您的客户体验、收入和竞争定位。将此视为纯粹的技术问题而非商业风险,就像假设您大楼的地基不是您关心的,因为您不是结构工程师——直到它破裂的那天,其上的一切都随之失败。
精明的领导者未来应该采取哪些不同做法?
2025年11月的Cloudflare中断事件为思考基础设施弹性战略的商业领袖提供了几个明确的教训。让我将其转化为可操作的路线图。
理解塑造基础设施风险的三大趋势
在我们深入具体建议之前,您需要理解三股力量,它们正使基础设施依赖既更有价值又更危险:
🔮 加速整合:基础设施市场继续围绕三大主要提供商——Cloudflare、亚马逊网络服务(AWS)和微软Azure——进行整合,较小的参与者在规模和成本效率上难以竞争。
🔧 自动化的双刃剑:能够在几秒钟内在全球范围内传播更改的快速部署系统,支持更快的创新和安全响应,但也意味着错误在人类干预成为可能之前就瞬间级联传播。
📈 加深的依赖:现代应用程序日益依赖数十个相互连接的服务,创造了一种依赖链,其中一个环节的故障可能不可预测地级联影响整个技术栈。
“数字备用发电机”框架
阿斯彭政策学院创始主任贝琪·库珀(Betsy Cooper)在分析这次中断时提出了一个引人入胜的类比:“我们需要数字备用发电机的等价物。” 就像医院和数据中心为电网故障时维持备用电源系统一样,企业需要冗余的基础设施能力,以应对主要云提供商发生中断的情况。
这实际上意味着什么?它并不意味着为所有东西运行重复的基础设施——那成本高昂且复杂得令人望而却步。它意味着为关键任务服务提供战略性冗余,并在主要系统故障时具备快速故障切换能力。
领导者的90天行动计划
以下是未来一个季度内提高您基础设施弹性的具体路线图:
1️⃣ 进行依赖关系审计(第1-2周): 映射所有关键业务服务,并识别它们依赖于哪些基础设施提供商,包括通过您的软件供应商产生的间接依赖。创建一个可视化的“依赖关系图”,显示单点故障。询问您的技术团队:“如果Cloudflare/AWS/Azure今天离线六小时,我们的哪些服务会故障?”
2️⃣ 计算您的风险敞口(第3-4周): 量化基础设施中断的业务影响,估算每个关键服务每小时的收入损失、生产力成本和SLA罚金。这将成为您投资弹性的商业案例。要现实——假设中断发生在业务高峰期,而不是在周日凌晨3点这种方便的时间。
3️⃣ 为关键服务实施多供应商策略(第5-8周): 对于您影响最大的服务,实施多CDN方法,结合基于DNS的负载均衡和自动故障切换。这并不意味着放弃您的主要提供商——而是拥有一个经过测试的备份,当主要提供商故障时自动激活。根据业务影响而非技术复杂性确定优先级。
4️⃣ 建立独立监控(第9-10周): 确保您的监控基础设施不依赖于正在被监控的服务。使用位于不同数据中心的多个监控提供商,以快速检测中断并区分是您的问题还是基础设施提供商的问题。
5️⃣ 测试您的备份计划(第11-12周): 在实际条件下真正测试您的故障切换程序,而不仅仅是记录它们。安排一次“消防演习”,您故意切换到备份基础设施并验证一切是否正常。大多数灾难恢复计划在纸上看起来很棒,但在第一次真实测试中就会失败。
6️⃣ 为质量而非价格做预算(持续进行): 当考虑到停机成本时,最便宜的基础设施选项很少是最好的价值。分配资源用于可靠性功能、冗余能力和经过验证的事件响应,而不是纯粹根据月费进行优化。
逆向思考案例:为何Cloudflare股票实际上颇具吸引力
这里有些可能让您惊讶的事情:尽管发生了这次灾难性的中断,我仍然认为Cloudflare股票在当前约196美元(低于中断前的202美元)的水平上代表着一个合理的投资。为什么?因为市场反应告诉我们一些关于投资者如何评估基础设施风险的重要信息。
Cloudflare的股票在11月18日最糟糕时下跌了7.0%,但在公司透明沟通并快速恢复服务后收盘仅下跌2.8%。这种相对温和的反应——将其与可能导致20-30%跌幅的数据泄露事件相比——表明投资者将此视为可恢复的运营事故,而非根本性的公司失败。
更重要的是,其基本财务状况依然强劲。2025年第三季度收入同比增长31%,达到5.62亿美元,而净亏损从1530万美元大幅减少至仅130万美元,显示出向盈利能力的明确迈进。在大多数分析师维持“买入”评级的情况下,市场基本上在说:“他们搞砸了,他们承担了责任,他们正在修复它,而且长期增长故事依然完整。”
对于商业领袖来说,这教会了一个关于危机应对的宝贵教训:透明度、快速补救和具体的预防措施,即使在发生严重的运营故障后,也能控制声誉损害。 首席执行官马修·普林斯(Matthew Prince)决定在12小时内亲自撰写一份详细的技术事后分析——包括实际出错的代码——展示了那种能快速重建信任的责任感。