🎯 Las interrupciones de servicios en la nube son eventos de continuidad del negocio – no solo problemas técnicos. El incidente de AWS DynamoDB demuestra cómo un solo fallo técnico puede propagarse a través de múltiples servicios, afectando las operaciones empresariales.
💰 Las implicaciones financieras van más allá del tiempo de inactividad – Las organizaciones enfrentan pérdidas de ingresos por fallos en transacciones, pérdida de clientes por indisponibilidad del servicio y costos de recuperación que pueden superar los presupuestos de TI planificados.
🚀 Las estrategias multirregión son esenciales – Las empresas que implementaron redundancia entre regiones mantuvieron sus operaciones durante la interrupción de AWS, mientras que aquellas dependientes de una sola región experimentaron disrupciones significativas.
⚠️ Las dependencias ocultas crean vulnerabilidades inesperadas – La mayoría de las organizaciones desconocen las complejas interdependencias entre los servicios en la nube hasta que una interrupción las revela, a menudo demasiado tarde para mitigar el impacto.
Imagina llegar a tu oficina y descubrir que la plataforma de comercio electrónico de tu empresa no funciona, los tickets de soporte al cliente se acumulan y tu equipo no puede implementar un parche de seguridad crítico. Tu CTO explica que se debe a «una condición de carrera en el DNS de AWS DynamoDB que se propagó a los servicios EC2 y NLB». Para la mayoría de los ejecutivos, esto suena como jerga técnica que pertenece al departamento de TI. Pero, ¿debería ser así?
En términos simples, las interrupciones de los servicios en la nube son eventos de continuidad del negocio que impactan directamente los ingresos, la confianza del cliente y la capacidad operativa. No son solo problemas técnicos, son problemas de negocio que requieren comprensión estratégica y atención ejecutiva.
Permíteme compartir una perspectiva desde mi experiencia liderando InterLIR, un mercado especializado en IPv4. Cuando falla la infraestructura en la nube, no es muy diferente a lo que sucede cuando las organizaciones enfrentan desafíos de disponibilidad de direcciones IP. Ambas situaciones generan un impacto inmediato en el negocio: los servicios se vuelven inaccesibles, las transacciones fallan y la experiencia del cliente se resiente. Los detalles técnicos importan menos que comprender las implicaciones comerciales y contar con estrategias para mantener las operaciones.
La interrupción del servicio de AWS en octubre de 2025 proporciona un caso de estudio perfecto. Lo que comenzó como un problema técnico aparentemente oscuro—una condición de carrera en el sistema de gestión de DNS de DynamoDB—se convirtió en una interrupción de 15 horas que afectó a miles de negocios en múltiples servicios. Las empresas sin estrategias adecuadas de resiliencia enfrentaron consecuencias operativas y financieras significativas.
En esta guía, desglosaré qué significan las interrupciones de los servicios en la nube en términos comerciales, explicaré por qué entender su funcionamiento es crítico para la planificación estratégica y proporcionaré un marco claro para tomar decisiones inteligentes sobre la resiliencia en la nube. No es necesario convertirse en un experto técnico, pero sí es necesario entender lo suficiente para hacer las preguntas correctas y asignar los recursos adecuadamente.
Las interrupciones tradicionales de TI generalmente afectan a un único sistema o ubicación. Cuando el servidor de correo de su empresa fallaba en el pasado, era un incidente aislado con límites claros. Las interrupciones de los servicios en la nube son fundamentalmente diferentes: son más como una reacción en cadena compleja que se propaga de manera impredecible a través de sistemas interconectados.
En los primeros días de la informática, la infraestructura era relativamente simple. Cada empresa mantenía sus propios servidores en un centro de datos dedicado. Cuando algo fallaba, el impacto estaba contenido y la ruta de resolución era clara: reparar o reemplazar el componente dañado. Como líder empresarial, podía ver y tocar su infraestructura, lo que hacía que los riesgos fueran tangibles y más fáciles de evaluar.
A medida que la tecnología evolucionó, este modelo se transformó drásticamente. La infraestructura en la nube actual se asemeja más a una ciudad vasta e interconectada que a una colección de edificios individuales. En esta metrópolis digital, los servicios son profundamente interdependientes, creando patrones de fallos complejos que pueden propagarse de formas inesperadas. Cuando un servicio crítico falla, puede desencadenar una cascada de fallos en sistemas aparentemente no relacionados, de manera similar a cómo un apagón en un distrito puede afectar el transporte, el comercio y las comunicaciones en toda una ciudad.
El incidente de AWS ejemplifica esta nueva realidad. Analicemos lo ocurrido en términos comerciales:
1️⃣ El fallo inicial – Una condición de carrera en el sistema de gestión de DNS de DynamoDB hizo que el servicio quedara inaccesible. Imaginen esto como la falla crítica en la estación de energía principal en nuestra analogía de la ciudad. 2️⃣ El efecto cascada – Este fallo inicial desencadenó problemas en EC2 (servicios de computación) y NLB (balanceadores de carga de red), que dependen de DynamoDB. En nuestra analogía de la ciudad, esto es como el apagón que hace fallar los semáforos, lo que a su vez genera un embotellamiento en todo el sistema de transporte. 3️⃣ El desafío de la recuperación – Incluso después de solucionar el problema inicial en DynamoDB, los sistemas secundarios permanecieron afectados debido a acumulaciones y tormentas de reintentos. Esto es similar a cómo la congestión vehicular persiste mucho después de que se restablecen los semáforos.Lo que hace esto particularmente desafiante es que la mayoría de las organizaciones no eran conscientes de estas dependencias hasta que experimentaron el impacto. Muchos líderes empresariales descubrieron vulnerabilidades críticas en su arquitectura en la nube solo después de que sus servicios ya se habían visto afectados.
Los servicios en la nube operan bajo un principio de abstracción: ocultan la complejidad para hacer que los sistemas sean más fáciles de usar. Si bien esto ofrece beneficios enormes, también oscurece la intrincada red de dependencias que puede afectar a su negocio. Considere esta comparación:
| Falla de TI tradicional | Interrupción de servicio en la nube | Implicación empresarial |
|---|---|---|
| Falla de hardware del servidor | Condición de carrera en DNS que desencadena fallos en cascada | Lo que parece una falla simple en un componente puede afectar múltiples funciones empresariales simultáneamente |
| Corte de red en su centro de datos | Degradación del servicio a nivel regional | La escala del impacto es órdenes de magnitud mayor |
| Claridad en la propiedad y control de la recuperación | Dependencia de los procesos de recuperación del proveedor de la nube | Capacidad limitada para influir directamente en los tiempos de resolución |
| Impacto predecible en sistemas específicos | Propagación impredecible entre servicios | Dificultad para evaluar el impacto empresarial total durante un incidente |
Esta diferencia fundamental requiere un nuevo enfoque para la planificación de la continuidad del negocio. El incidente de AWS demuestra que las decisiones de arquitectura técnica tienen implicaciones comerciales directas que van mucho más allá del departamento de TI. Comprender estas implicaciones es ahora una responsabilidad central del liderazgo empresarial.
Cuando los servicios en la nube fallan, los impactos van mucho más allá de métricas técnicas como «tiempo de inactividad del sistema» o «tasas de error». Se traducen directamente en consecuencias comerciales que afectan los ingresos, la experiencia del cliente, la capacidad operativa e incluso el cumplimiento normativo. Examinemos estos impactos a través del lente del incidente de AWS.

Durante la interrupción de AWS, las empresas experimentaron varios impactos directos en los ingresos:
💸 Fallos en transacciones – Las plataformas de comercio electrónico que dependían de DynamoDB para el inventario o el procesamiento de pagos experimentaron transacciones fallidas. Un cliente minorista informó pérdidas de aproximadamente $150,000 en ventas durante un período de cuatro horas en el que su proceso de pago no estuvo disponible.
🔄 Interrupciones en la gestión de suscripciones – Las empresas SaaS que utilizaban los servicios afectados para la gestión de suscripciones enfrentaron dificultades para procesar nuevas suscripciones y renovaciones, generando pérdidas de ingresos.
📉 Ineficacia de campañas de marketing – Las empresas que ejecutaban promociones sensibles al tiempo vieron sus campañas afectadas cuando los clientes no pudieron completar compras, desperdiciando gastos en marketing y oportunidades.
Lo que es particularmente notable es cómo estos impactos variaron según las decisiones de arquitectura. Las empresas que habían implementado estrategias multirregión mantuvieron al menos una funcionalidad parcial, mientras que aquellas dependientes de una sola región enfrentaron interrupciones completas. Esto demuestra cómo las decisiones de arquitectura técnica influyen directamente en la resiliencia empresarial y la protección de ingresos.
Más allá de los impactos directos en los ingresos, la interrupción afectó la capacidad de las organizaciones para operar de manera efectiva:
🚫 Congelamiento de despliegues – Las organizaciones no pudieron lanzar nuevas instancias EC2, lo que las obligó a retrasar lanzamientos de software planeados y el escalado de infraestructura. Una empresa de servicios financieros tuvo que posponer la implementación de un parche de seguridad crítico por 24 horas.
🔍 Ceguera en el monitoreo – Muchas empresas perdieron visibilidad de sus sistemas cuando las herramientas de monitoreo dependientes de los servicios afectados dejaron de funcionar, limitando su capacidad para evaluar el impacto y responder eficazmente.
🧯 Limitaciones en la respuesta a incidentes – Los equipos técnicos se vieron incapaces de implementar procedimientos estándar de remediación que requerían lanzar nuevos recursos o acceder a servicios afectados.
Estos impactos operativos a menudo generaron consecuencias comerciales secundarias que se extendieron más allá de la interrupción técnica en sí. Por ejemplo, el retraso en la implementación del parche de seguridad mencionado anteriormente generó un riesgo de cumplimiento que requirió notificación a los reguladores.
Quizás el impacto comercial más significativo se dio a través de la degradación de la experiencia del cliente:
😠 Aumento en el volumen de soporte – Las empresas reportaron un incremento del 300-500% en los tickets de soporte durante la interrupción, saturando a los equipos y generando desafíos operativos adicionales.
🔁 Experiencias repetitivas de errores – Los clientes que intentaban utilizar los servicios encontraron mensajes de error frustrantes o indicadores de carga interminables, creando asociaciones negativas con la marca.
💔 Erosión de la confianza – Para servicios donde la confiabilidad es un valor clave (servicios financieros, atención médica, herramientas empresariales críticas), la interrupción dañó la percepción y la confianza en la marca.
El impacto en la experiencia del cliente a menudo duró más que la interrupción técnica en sí. En nuestro trabajo en InterLIR, hemos observado que la confianza del cliente tarda aproximadamente 2-3 veces más en recuperarse que el servicio en sí. Esto crea una «deuda de confianza» que las empresas deben trabajar por saldar mediante una confiabilidad consistente después de un incidente.
Al calcular el costo empresarial real de las interrupciones en la nube, los líderes deben considerar múltiples factores:
| Categoría de Costo | Ejemplos | Método de Cálculo |
|---|---|---|
| Pérdida Directa de Ingresos | Transacciones fallidas, interrupciones de suscripción | Volumen de transacciones × valor promedio × porcentaje de interrupción |
| Costos Operativos | Horas extras, respuesta de emergencia, esfuerzos de recuperación | Horas laborales adicionales × costo total cargado |
| Impacto al Cliente | Aumento de soporte, daño a la reputación, abandono de clientes | Aumento en volumen de soporte × costo de manejo + valor estimado de abandono |
| Costos de Oportunidad | Lanzamientos retrasados, desventaja competitiva | Valor estimado de iniciativas retrasadas |
| Consecuencias Regulatorias | Reportes regulatorios, posibles multas | Costos directos + multas potenciales ajustadas por riesgo |
Esta visión integral del impacto empresarial debe orientar tanto las prioridades de recuperación durante un incidente como las decisiones de inversión para estrategias de resiliencia. Las organizaciones que superaron la interrupción de AWS con mayor eficacia fueron aquellas que previamente habían realizado este análisis e invertido en consecuencia.
Construir resiliencia en la nube no se trata solo de implementar las soluciones técnicas más robustas, sino de realizar inversiones estratégicas basadas en prioridades empresariales. El incidente de AWS proporciona información valiosa sobre enfoques efectivos que equilibran el costo con la protección.
La resiliencia en la nube existe en un espectro, con diferentes enfoques que ofrecen distintos niveles de protección en varios puntos de costo:
🔹 Resiliencia básica – Centrada en la recuperación más que en la continuidad, este enfoque acepta cierto tiempo de inactividad pero garantiza que los datos estén protegidos y los servicios puedan restaurarse. Es adecuado para funciones empresariales no críticas.
🔶 Resiliencia mejorada – Implementa redundancia dentro de una región y capacidades básicas entre regiones para los componentes más críticos. Este enfoque puede mantener la funcionalidad central durante muchos tipos de interrupciones.
🔷 Resiliencia avanzada – Utiliza arquitecturas activo-activo multirregión con conmutación por error automatizada. Este enfoque mantiene operaciones casi continuas, pero con un costo y complejidad significativamente mayores.
Durante el incidente de AWS, las organizaciones en este espectro experimentaron resultados dramáticamente diferentes. Aquellas con resiliencia básica enfrentaron interrupciones completas, mientras que aquellas con resiliencia avanzada mantuvieron operaciones con un impacto mínimo. Sin embargo, la clave es que la resiliencia dirigida—aplicar el nivel de protección adecuado a cada función empresarial según su criticidad—proporcionó el mejor retorno de inversión.
Basado en el incidente de AWS y nuestra experiencia en InterLIR trabajando con organizaciones que gestionan recursos de red críticos, recomiendo estos enfoques estratégicos:
1️⃣ Priorización de funciones empresariales – Clasifique sus funciones empresariales por criticidad, considerando tanto el impacto en los ingresos como la experiencia del cliente. Esto crea un marco claro para las decisiones de inversión en resiliencia. 2️⃣ Mapeo de dependencias – Identifique la cadena completa de dependencias de servicios en la nube para cada función empresarial crítica. El incidente de AWS demostró cómo las dependencias ocultas pueden socavar las estrategias de resiliencia. 3️⃣ Implementación multi-región dirigida – Aplique arquitecturas multi-región primero a sus funciones más críticas. Durante el incidente de AWS, incluso una implementación parcial multi-región proporcionó una protección significativa. 4️⃣ Diseño de degradación gradual – Diseñe sistemas para mantener la funcionalidad básica incluso cuando algunos componentes no estén disponibles. Este enfoque brindó una protección empresarial sustancial a un costo moderado. 5️⃣ Pruebas de resiliencia periódicas – Valide sus estrategias de resiliencia mediante pruebas controladas. Las organizaciones que ya habían probado escenarios de fallas regionales respondieron con mayor eficacia durante el incidente real.Este enfoque estratégico permite a las organizaciones lograr una resiliencia significativa sin el costo prohibitivo de implementar protección avanzada para todos los sistemas. Se trata de hacer inversiones inteligentes basadas en prioridades empresariales.
Varios patrones técnicos específicos demostraron ser particularmente efectivos durante el incidente de AWS, manteniendo perfiles de costos razonables:
💡 Réplicas de lectura entre regiones – Las organizaciones que replicaron datos de solo lectura entre regiones mantuvieron la capacidad de recuperar información incluso cuando las operaciones de escritura se vieron afectadas. Este patrón tiene un costo significativamente menor que las implementaciones activo-activo completas, preservando capacidades críticas.
💡 Contenidos estáticos alternativos – Los servicios que implementaron contenidos estáticos alternativos mantuvieron experiencias básicas para los clientes durante la interrupción. Este patrón simple brindó una protección sustancial de la marca con un costo mínimo.
💡 Circuit breakers y bulkheads – Los sistemas diseñados para aislar fallas evitaron el efecto en cascada que amplificó la interrupción de AWS. Estos patrones arquitectónicos agregan un costo mínimo mientras mejoran significativamente la resiliencia.
💡 Procesamiento asíncrono – Las organizaciones que diseñaron sistemas para encolar operaciones y procesarlas posteriormente mantuvieron la funcionalidad durante la interrupción y se recuperaron más rápidamente después.
Lo que es particularmente notable de estos patrones es que no requieren duplicar infraestructuras completas entre regiones. En cambio, se centran en mantener capacidades críticas mediante estrategias de resiliencia específicas. Este enfoque brinda una protección empresarial sustancial a una fracción del costo de una redundancia completa.

Alexander Timokhin
CEO
InterLIR GmbH es un marketplace de rápido crecimiento enfocado en abordar los problemas
La utilización eficiente del espacio de direcciones IPv4 existente es un enfoque
Incluso si no planeas vender tu bloque IPv4, aún hay formas de obtener ganancias
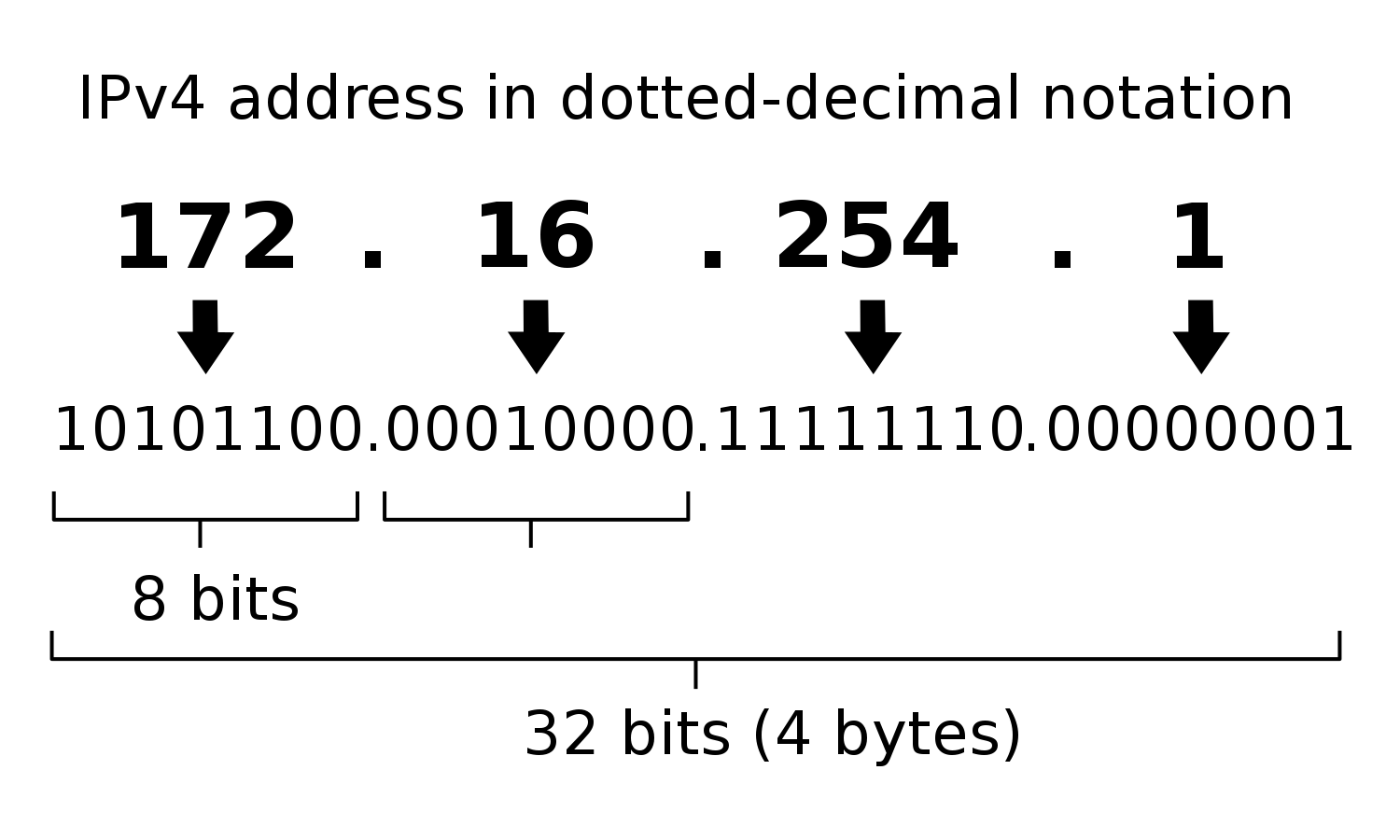
Una dirección de Protocolo de Internet (IP) es un identificador único asignado
La creciente demanda de bloques de direcciones IP ha elevado los precios y ha convertido
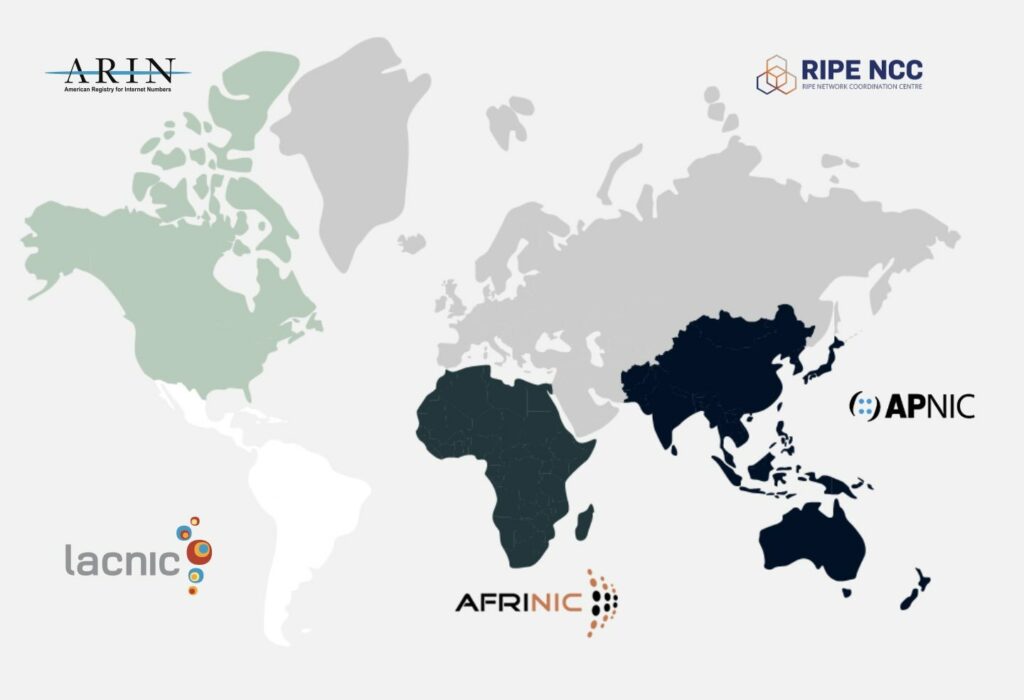
Todo lo que necesitas saber sobre la política de transferencia, fusión, adquisición
Esta política permite transferir direcciones IP solo dentro de la región. Además,
La política de transferencia inter-RIR permite la utilización eficiente del espacio
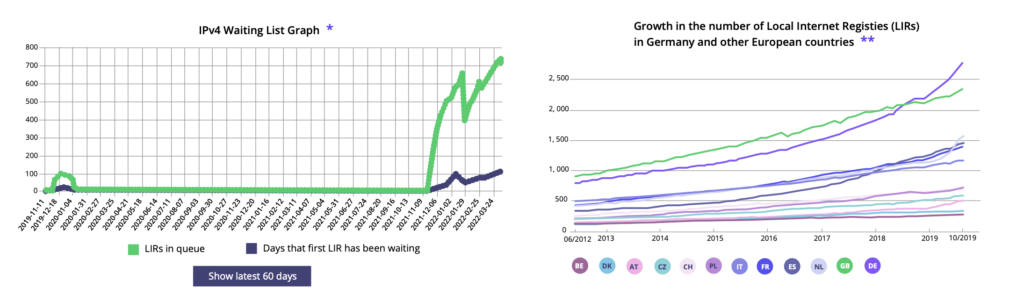
La agotación de direcciones IPv4 es un problema urgente, y las empresas se están