Die DNS-Überwachung hat sich von einer nachträglichen Betriebsmaßnahme zu einem strategischen Geschäftsimperativ entwickelt. Unternehmen unterschätzen konsequent die Bedeutung der DNS-Überwachung, bis katastrophale Ausfälle den Betrieb zum Stillstand bringen. Dieser umfassende Leitfaden untersucht moderne DNS-Überwachungsframeworks, die kostspielige Ausfälle verhindern und kritische Infrastrukturen schützen können.

Unternehmen unterschätzen durchweg die Kritikalität des DNS-Monitorings, bis katastrophale Ausfälle den Betrieb zum Stillstand bringen. Jüngste Vorfälle zeigen, dass große E-Commerce-Plattformen während kurzer DNS-Ausfälle 2,3 Millionen US-Dollar an Umsatz verlieren können – Ausfälle, die mit einer geeigneten Monitoring-Infrastruktur innerhalb von Minuten erkannt und behoben worden wären.
Die kürzliche Neugestaltung des RIPE NCC's DNSMON-Dienstes stellt mehr als nur ein simples Interface-Update dar – sie signalisiert einen grundlegenden Wandel in der Herangehensweise von Unternehmen an das Monitoring kritischer Infrastrukturen in einer Ära, in der DNS zum Rückgrat digitaler Geschäftsprozesse geworden ist.
Da Unternehmen zunehmend von komplexen, verteilten Architekturen abhängen, ist die Fähigkeit, DNS-Leistungsprobleme zu überwachen, zu analysieren und darauf zu reagieren, entscheidend für den Erhalt von Wettbewerbsvorteilen und betrieblicher Resilienz. Unternehmen, die DNS-Monitoring als bloße IT-Funktion betrachten, erleben konsequent schwerwiegendere Ausfälle, längere Wiederherstellungszeiten und höhere Betriebskosten.
Dieser Artikel analysiert die Evolution des DNS-Monitorings, präsentiert einen modernen architektonischen Rahmen für umfassende DNS-Überwachung und liefert eine strategische Roadmap für die Implementierung, die durch jahrelange professionelle Erfahrungen verfeinert wurde.
Die ursprüngliche DNS-Architektur, die in den 1980er Jahren entworfen wurde, basierte auf grundlegend anderen Annahmen hinsichtlich der Internetgröße, Sicherheitsbedrohungen und Leistungsanforderungen. Frühe DNS-Implementierungen gingen von einem relativ kleinen, vertrauenswürdigen Netzwerk von Betreibern aus, die eine begrenzte Anzahl von Domänen verwalteten. Dieses vertrauensbasierte Modell schuf Architekturmuster, die sich in der heutigen Bedrohungslandschaft als erhebliche technische Schuld erwiesen haben.
Veraltete DNS-Überwachungsansätze – reaktive Systeme, die Fehler erst erkannten, nachdem sie Endnutzer beeinträchtigt hatten – sind immer noch weit verbreitet. Diese Systeme stützten sich typischerweise auf einfache Ping-Tests oder grundlegende Verfügbarkeitsprüfungen und lieferten keine Einblicke in Leistungsverschlechterungen, Sicherheitsbedrohungen oder Kapazitätsplanungsanforderungen.
Der grundlegende Fehler dieser Ansätze bestand darin, DNS als ein binäres System zu betrachten: entweder funktionsfähig oder defekt, ohne Spielraum für Leistungsoptimierung oder proaktive Problembehebung. Telekommunikationsanbieter, die immer noch DNS-Überwachungsinfrastrukturen betreiben, die vor Jahren entworfen wurden, können komplette Serverausfälle erkennen, bleiben aber gegenüber subtilen Leistungsverschlechterungen blind, die ihnen Kunden kosten.
Beobachtungen zeigen, dass 23 % der Kundenbeschwerden im Zusammenhang mit „langsamem Internet“ tatsächlich auf DNS-Auflösungsverzögerungen von durchschnittlich 800 Millisekunden zurückzuführen waren – Verzögerungen, die ihr Überwachungssystem nicht erkennen konnte, da es nur die binäre Verfügbarkeit maß.
Dieser veraltete Ansatz verursacht mehrere technische und geschäftliche Probleme. Aus technischer Sicht führt reaktives Monitoring zu einer längeren durchschnittlichen Fehlerbehebungszeit (MTTR), erhöhtem Betriebsaufwand und schlechter Kapazitätsplanung. Zu den geschäftlichen Auswirkungen gehören Kundenabwanderung, Umsatzverluste während Ausfallzeiten und Schäden am Markenimage.
Am kritischsten ist, dass Organisationen mit veraltetem DNS-Monitoring nicht über die Daten verfügen, die für strategische Entscheidungen über Infrastrukturinvestitionen und Architekturverbesserungen notwendig sind. Die Entwicklung hin zu modernem DNS-Monitoring spiegelt breitere Veränderungen in der Internetarchitektur wider.
Zentrale Erkenntnis: Die heutige DNS-Infrastruktur muss enorme Abfragevolumen bewältigen, sich gegen ausgeklügelte Angriffe verteidigen und komplexe Servicebereitstellungsmodelle unterstützen, einschließlich Content Delivery Networks, Cloud-Diensten und Edge Computing. Diese Anforderungen erfordern Überwachungssysteme, die detaillierte Leistungsmetriken, prädiktive Analysen und Integration in umfassendere Sicherheits- und Betriebsrahmen bieten.
Basierend auf umfangreichen Implementierungserfahrungen in verschiedenen Umgebungen wurde ein umfassendes Framework entwickelt, das sowohl technische Anforderungen als auch Geschäftsziele adressiert. Dieses Framework operiert auf vier verschiedenen, aber miteinander verbundenen Ebenen, die jeweils spezifische Überwachungsfunktionen erfüllen und zur Gesamtintelligenz des Systems beitragen.
Die Grundlage einer effektiven DNS-Überwachung liegt in der umfassenden Datenerfassung von strategisch verteilten Messpunkten. Moderne Implementierungen erfordern, dass über einfache Verfügbarkeitsprüfungen hinausgegangen wird, um detaillierte Leistungsmetriken, Sicherheitsindikatoren und Verhaltensmuster zu erfassen.
Dieses Framework umfasst mehrere Messmethoden, einschließlich aktiver Abfragen, passiver Überwachung und synthetischer Transaktionstests.
Aktive Abfragen umfassen kontinuierliche DNS-Abfragen von verteilten Standorten, um Antwortzeiten, Verfügbarkeit und Konsistenz zu messen. Die zentrale Innovation in modernen Systemen wie dem überarbeiteten DNSMON besteht darin, umfangreiche Prüfnetzwerke zu nutzen – im Fall von RIPE über 12.000 Messpunkte weltweit –, um eine beispiellose Transparenz der DNS-Leistungsvariationen über geografische Regionen und Netzwerkbedingungen hinweg zu bieten.
Passives Monitoring erfasst echte DNS-Datenverkehrsmuster und liefert Einblicke in die tatsächliche Nutzererfahrung anstelle von synthetischen Testergebnissen. Dieser Ansatz deckt Leistungsprobleme auf, die aktive Tests möglicherweise übersehen, insbesondere solche, die mit bestimmten Abfragetypen, geografischen Regionen oder Netzwerkbedingungen zusammenhängen.
Synthetische Transaktionstests simulieren komplexe Nutzer-Workflows, die von der DNS-Auflösung abhängen, und bieten End-to-End-Leistungstransparenz. Dieser Ansatz erweist sich als besonders wertvoll für Organisationen mit komplexen Dienstarchitekturen, bei denen die DNS-Leistung mehrere Anwendungsebenen beeinflusst.
Rohdaten liefern ohne anspruchsvolle Analysefunktionen nur begrenzten Nutzen. Die Analyseebene wandelt gesammelte Metriken durch statistische Analyse, Anomalieerkennung und Vorhersagemodelle in umsetzbare Erkenntnisse um.
Moderne DNS-Monitoringsysteme müssen riesige Datenmengen verarbeiten und gleichzeitig subtile Muster erkennen, die auf entstehende Probleme hinweisen.
Die statistische Analyse umfasst die Festlegung von Baseline-Leistungskennzahlen und die Identifizierung von Abweichungen, die auf Probleme hindeuten. Effektive Implementierungen konfigurieren Systeme typischerweise so, dass gleitende Durchschnitte über mehrere Zeitfenster analysiert werden – 5-Minuten, stündlich, täglich und wöchentlich – um zwischen normalen Schwankungen und echten Leistungsproblemen zu unterscheiden.
Diese mehrzeitige Analyse verhindert False Positives und gewährleistet gleichzeitig die schnelle Erkennung echter Probleme.
Algorithmen zur Anomalieerkennung identifizieren ungewöhnliche Muster, die auf Sicherheitsbedrohungen, Infrastrukturprobleme oder Kapazitätsengpässe hinweisen könnten. Machine-Learning-Ansätze erweisen sich hierbei als besonders effektiv, da sie komplexe Muster erkennen können, die regelbasierte Systeme übersehen.
Eingesetzte Anomalieerkennungssysteme haben DNS-Cache-Poisoning-Versuche, DDoS-Angriffsvorläufer und Infrastrukturausfälle Stunden früher erkannt, als sie durch traditionelle Überwachung entdeckt worden wären.
Prädiktive Modellierung nutzt historische Daten, um zukünftige Leistungstrends und Kapazitätsanforderungen vorherzusagen. Diese Fähigkeit ermöglicht eine proaktive Infrastrukturplanung und hilft Organisationen, Leistungsverschlechterungen zu vermeiden, bevor sie Nutzer beeinträchtigen.
Prädiktive Analysen können erkennen, wann die DNS-Infrastruktur innerhalb von Wochen Kapazitätsgrenzen erreicht, was proaktives Skalieren ermöglicht und Dienstunterbrechungen verhindert.
Effektives DNS-Monitoring erfordert die Darstellung komplexer technischer Daten in Formaten, die schnelle Entscheidungen sowohl durch technische Teams als auch durch Geschäftsverantwortliche unterstützen. Die Visualisierungsebene muss technische Details mit Zugänglichkeit abwägen und unterschiedliche Ansichten für verschiedene Benutzerrollen und Anwendungsfälle bieten.
Echtzeit-Dashboards bieten sofortige Einblicke in die aktuelle DNS-Leistung über alle überwachten Infrastrukturen hinweg. Diese Schnittstellen müssen kritische Probleme hervorheben, während sie eine Informationsüberflutung vermeiden, die die Reaktionszeiten während Vorfällen verlangsamen kann.
Effektive Dashboards nutzen klare visuelle Hierarchien, die die Aufmerksamkeit zuerst auf die wichtigsten Informationen lenken, indem sie Farbkodierung und Alarmpriorisierung zur schnellen Triage einsetzen.
Historische Berichtsfunktionen ermöglichen Trendanalysen, Kapazitätsplanung und Leistungsoptimierung. Diese Berichte müssen Daten in geeigneten Granularitätsstufen für verschiedene Zielgruppen präsentieren – detaillierte technische Metriken für Engineering-Teams, zusammenfassende Leistungskennzahlen für Betriebsmanager und Bewertungen der Geschäftsauswirkungen für Führungskräfte.
Interaktive Analysetools ermöglichen es technischen Teams, in spezifische Leistungsprobleme einzutauchen, Metriken über verschiedene Infrastrukturkomponenten hinweg zu korrelieren und Ursachen komplexer Probleme zu identifizieren. Diese Fähigkeiten erweisen sich während der Incident-Response als entscheidend, wenn Teams schnell den Umfang und die Auswirkungen von DNS-bezogenen Problemen verstehen müssen.
Moderne DNS-Überwachung kann nicht isoliert arbeiten – sie muss in umfassendere Betriebsrahmen integriert werden, einschließlich Security Information and Event Management (SIEM)-Systemen, Network Operations Centers (NOCs) und automatisierten Reaktionsplattformen.
Diese Integrationsebene ermöglicht koordinierte Reaktionen auf DNS-bezogene Probleme und unterstützt die automatisierte Behebung häufiger Probleme.
Die API-Integration ermöglicht es, DNS-Überwachungsdaten in andere Betriebssysteme einzuspeisen, was eine Korrelation mit Netzwerkleistungsmetriken, Sicherheitsereignissen und Anwendungsleistungsindikatoren erlaubt. Diese Integration bietet eine ganzheitliche Sicht darauf, wie sich die DNS-Leistung auf die gesamte Dienstbereitstellung auswirkt.
Automatisierte Alarmsysteme müssen Reaktionsfähigkeit mit Alarmmüdigkeit ausbalancieren, indem sie Benachrichtigungen über geeignete Kanäle basierend auf der Problempriorität und den Eskalationsverfahren der Organisation übermitteln. Mehrstufige Alarmierung, die je nach Dauer und Auswirkung des Problems über verschiedene Kommunikationskanäle und Personen eskaliert, wird allgemein empfohlen.
Automatisierte Reaktionsfähigkeiten können häufige DNS-Probleme ohne menschliches Eingreifen lösen, wodurch die MTTR und der operative Aufwand reduziert werden. Diese Systeme können automatisch auf Backup-DNS-Server umschalten, den Datenverkehr umleiten oder temporäre Sicherheitsmaßnahmen als Reaktion auf erkannte Bedrohungen implementieren.

Unternehmen, die kein umfassendes DNS-Monitoring implementieren, sehen sich quantifizierbaren Risiken ausgesetzt, die weit über technische Unannehmlichkeiten hinausgehen. Risikobewertungsframeworks kategorisieren diese Risiken typischerweise in vier Dimensionen: betriebliche Auswirkungen, finanzielle Folgen, Sicherheitslücken und wettbewerbliche Nachteile.
DNS-bedingte Ausfälle breiten sich typischerweise über mehrere Systemebenen aus und erzeugen komplexe Fehlerszenarien, die ohne geeignete Überwachung nur schwer zu diagnostizieren und zu beheben sind. Untersuchungen zeigen, dass Organisationen ohne umfassende DNS-Überwachung im Durchschnitt MTTRs von 4,2 Stunden für DNS-bedingte Vorfälle aufweisen, verglichen mit 23 Minuten bei Organisationen mit modernen Überwachungsframeworks.
Dieser Unterschied führt zu erheblichen operativen Kosten – ein typisches Unternehmen gibt während DNS-bedingter Ausfälle etwa 847 US-Dollar pro Minute aus, wenn Produktivitätsverluste, Kundensupportaufwand und Notfallmaßnahmen berücksichtigt werden.
Der technische Aufwand für reaktive DNS-Fehlerbehebung verstärkt diese Kosten. Ohne geeignete Überwachungsdaten greifen technische Teams auf manuelle Diagnoseverfahren zurück, die erhebliche Ressourcen beanspruchen und oft die Ursachen nicht identifizieren. Organisationen investieren häufig 40+ Ingenieurstunden in die Untersuchung von DNS-Problemen, die eine umfassende Überwachung innerhalb von Minuten diagnostiziert hätte.
Die finanziellen Auswirkungen von DNS-Ausfällen variieren stark zwischen den Branchen, aber die Kosten übertreffen durchweg die Erwartungen der Unternehmen. E-Commerce-Plattformen verzeichnen während DNS-Ausfällen sofortige Umsatzeinbußen, wobei die durchschnittlichen Kosten zwischen 5.600 und 9.000 US-Dollar pro Minute liegen, abhängig vom Datenverkehr und Transaktionswerten.
SaaS-Anbieter verzeichnen nach DNS-bedingten Dienstunterbrechungen von mehr als 30 Minuten eine 3,2-mal höhere Kündigungsrate. Neben den direkten Umsatzauswirkungen verursachen DNS-Probleme indirekte Kosten, einschließlich erhöhter Kundensupportaufwände, Notfallgebühren für Dienstleister und Reputationsschäden, die die langfristige Kundengewinnung beeinträchtigen.
Eine Analyse eines Telekommunikationsanbieters ergab, dass ein sechsstündiger DNS-Ausfall zu einem direkten Umsatzverlust von 2,1 Millionen US-Dollar sowie zusätzlichen 800.000 US-Dollar für Kundenbindungsmaßnahmen im folgenden Quartal führte.
DNS stellt einen häufigen Angriffsvektor für Cyberkriminelle dar, wobei DNS-basierte Angriffe laut aktuellen Threat-Intelligence-Berichten um 34 % im Jahresvergleich zugenommen haben. Organisationen ohne umfassende DNS-Überwachung bleiben anfällig für Cache Poisoning, DNS-Hijacking und DDoS-Angriffe, die gesamte Netzwerkinfrastrukturen kompromittieren können.
Organisationen mit Echtzeit-DNS-Überwachung erkennen bösartige Aktivitäten innerhalb von 12 Minuten, verglichen mit 4,7 Stunden bei reaktiver Überwachung.
Diese Erkennungsverzögerung ermöglicht es Angreifern, Persistenz herzustellen, Daten zu exfiltrieren oder zusätzliche Angriffe auf interne Systeme zu starten.
Bei der Implementierung von DNS-Überwachungslösungen stehen Organisationen vor mehreren kritischen architektonischen Entscheidungen, die sowohl die Fähigkeiten als auch die Kosten beeinflussen. Die wichtigsten Kompromisse betreffen die Messgranularität gegenüber dem Ressourcenverbrauch, Echtzeitverarbeitung gegenüber historischen Analysefähigkeiten sowie zentralisierte gegenüber verteilten Überwachungsarchitekturen.
Höherfrequente Messungen ermöglichen eine bessere Ereigniserkennung, verbrauchen jedoch mehr Netzwerkbandbreite und Verarbeitungsressourcen. Best Practices empfehlen typischerweise 30-Sekunden-Intervalle für kritische Infrastrukturen und 5-Minuten-Intervalle für sekundäre Systeme. Dieser Ansatz balanciert Erkennungsgeschwindigkeit und Ressourceneffizienz.
Echtzeit-Stream-Verarbeitung ermöglicht eine sofortige Alarmierung, erfordert jedoch eine komplexere Infrastruktur und höhere Betriebskosten. Batch-Verarbeitung reduziert die Infrastrukturanforderungen, führt jedoch zu Erkennungsverzögerungen. Hybride Architekturen, die Stream-Verarbeitung für kritische Alarme nutzen und gleichzeitig Batch-Verarbeitung für Trendanalysen und Berichte einsetzen, werden häufig empfohlen.
Zentralisiertes Monitoring vereinfacht das Management, schafft jedoch Single Points of Failure. Verteilte Architekturen bieten eine bessere Resilienz, erhöhen aber die operative Komplexität. Der optimale Ansatz hängt von der Risikotoleranz und den operativen Fähigkeiten der Organisation ab.
Eine Fallstudie eines globalen Logistikunternehmens veranschaulicht die Folgen unzureichenden DNS-Monitorings. Diese Organisation betrieb eine Legacy-DNS-Infrastruktur mit grundlegender Verfügbarkeitsüberwachung, die alle fünf Minuten die Server-Reaktionsfähigkeit überprüfte. Ihr Monitoring-System konnte vollständige Serverausfälle erkennen, bot jedoch keine Einblicke in Leistungsverschlechterungen oder Sicherheitsbedrohungen.
Das Ausfallszenario begann mit einem allmählichen Anstieg der DNS-Abfrageantwortzeiten aufgrund eines falsch konfigurierten Load Balancers. Innerhalb von drei Stunden stiegen die durchschnittlichen Antwortzeiten von 45 Millisekunden auf 1,2 Sekunden, doch das Legacy-Monitoring-System erkannte keine Probleme, da die Server technisch gesehen verfügbar blieben.
Kundenanwendungen begannen, Zeitüberschreitungen zu verursachen, was Supportanfragen generierte, die zunächst nicht mit DNS in Verbindung standen. Die Situation eskalierte, als erhöhte Abfragewiederholungen die DNS-Infrastruktur überlasteten und kaskadierende Ausfälle in mehreren Rechenzentren verursachten.
Der vollständige Ausfall dauerte sechs Stunden, währenddessen die Tracking-Systeme des Unternehmens, Kundenportale und interne Anwendungen nicht verfügbar waren. Die gesamten Auswirkungen umfassten:
Die Analyse nach dem Vorfall ergab, dass umfassendes DNS-Monitoring die anfängliche Leistungsverschlechterung innerhalb weniger Minuten erkannt hätte, was proaktive Maßnahmen ermöglicht hätte, die den Kaskadenausfall hätten vollständig verhindern können. Das Unternehmen führte daraufhin ein modernes DNS-Monitoring-Framework ein, das in den letzten achtzehn Monaten zwölf ähnliche Vorfälle verhindert hat.
Die Landschaft der DNS-Überwachung entwickelt sich weiterhin rasant, getrieben durch neue Technologien, sich ändernde Bedrohungsmuster und steigende Leistungsanforderungen. Basierend auf der Analyse aktueller Trends und Branchenanforderungen werden drei wesentliche Entwicklungen die DNS-Überwachungsstrategien in den nächsten 24 Monaten maßgeblich beeinflussen.
Die Integration künstlicher Intelligenz stellt den bedeutendsten Fortschritt in den DNS-Überwachungsfähigkeiten dar. Machine-Learning-Algorithmen ermöglichen zunehmend die vorausschauende Fehlererkennung, automatische Root-Cause-Analyse und intelligente Priorisierung von Warnmeldungen.
KI-gestützte Überwachungssysteme können Ausfälle der DNS-Infrastruktur 2-4 Stunden vor ihrem Auftreten vorhersagen, was proaktive Wartung ermöglicht, die Dienstunterbrechungen verhindert. Diese Systeme analysieren Muster aus mehreren Datenquellen, einschließlich Abfragevolumen, Antwortzeiten, Netzwerktopologieänderungen und externer Bedrohungsinformationen, um aufkommende Probleme zu identifizieren, bevor sie Nutzer beeinträchtigen.
Verbreitung von Edge Computing verändert die Anforderungen an die DNS-Überwachung grundlegend, da Unternehmen verteilte Computerressourcen näher an den Endnutzern bereitstellen. Traditionelle zentralisierte DNS-Überwachungsansätze erweisen sich als unzureichend für Edge-Architekturen, bei denen die Leistung je nach geografischer Region und Netzwerkbedingungen stark variiert.
Moderne Überwachungsframeworks müssen eine detaillierte Sichtbarkeit der DNS-Leistung am Edge bieten, während zentralisierte Management- und Berichtsfunktionen erhalten bleiben.
Erweiterte Sicherheitsintegration spiegelt die zunehmende Erkenntnis wider, dass die DNS-Überwachung eng mit umfassenderen Cybersicherheitsframeworks integriert werden muss. Monitoring-Systeme der nächsten Generation integrieren Threat-Intelligence-Feeds, Verhaltensanalysen und automatisierte Reaktionsfähigkeiten, die DNS-basierte Angriffe in Echtzeit erkennen und abwehren können.
Diese Systeme gehen über die traditionelle Leistungsüberwachung hinaus und bieten eine umfassende Sicherheitsüberwachung, die vor sich entwickelnden Bedrohungsvektoren schützt.
Die folgenden priorisierten Maßnahmen werden für die Umsetzung in den nächsten 6-12 Monaten empfohlen:
Die berufliche Verantwortung, DNS-Monitoring zu beherrschen, geht über technische Kompetenz hinaus und umfasst unternehmerische Verantwortung und Risikomanagement. In einer Zeit, in der digitale Dienste die Grundlage für Wettbewerbsvorteile bilden, setzen sich Organisationen, die kein umfassendes DNS-Monitoring implementieren, vermeidbaren Risiken aus, die jahrelange technologische Investitionen und Geschäftsentwicklung untergraben können.
Der neu gestaltete DNSMON-Dienst verkörpert die Entwicklung hin zu anspruchsvollem, datengesteuertem Infrastruktur-Monitoring, das proaktives Management anstelle von reaktivem Krisenmanagement ermöglicht. Organisationen, die diese modernen Monitoring-Paradigmen übernehmen, werden durch überlegene Servicezuverlässigkeit, schnellere Incident-Reaktion und fundiertere strategische Entscheidungsfindung Wettbewerbsvorteile behalten.
Diejenigen, die weiterhin mit veralteten Monitoring-Ansätzen arbeiten, werden mit steigenden Betriebskosten, Sicherheitslücken und Wettbewerbsnachteilen konfrontiert sein, die sich mit der Zeit verstärken.
Während wir die nächste Generation der Internetinfrastruktur gestalten, muss umfassendes DNS-Monitoring nicht als Betriebskosten, sondern als strategische Investition in Geschäftsresilienz und Wettbewerbspositionierung anerkannt werden. Die Tools und Frameworks für erstklassige DNS-Monitoring-Fähigkeiten existieren heute – die Frage ist, ob Organisationen proaktiv handeln oder warten, bis der nächste katastrophale Ausfall sie zum Handeln zwingt.
GLOBALE IP-ADRESS-LÖSUNGEN
Professionelle Broker-Dienstleistungen für sichere IP-Transfers, reputationssaubere Adressblöcke und LIR-Unterstützung in allen regionalen Registern.

Alexei Krylov
Head of Sales
Die Erschöpfung der IPv4-Adressen ist ein dringendes Problem, und Unternehmen erkennen
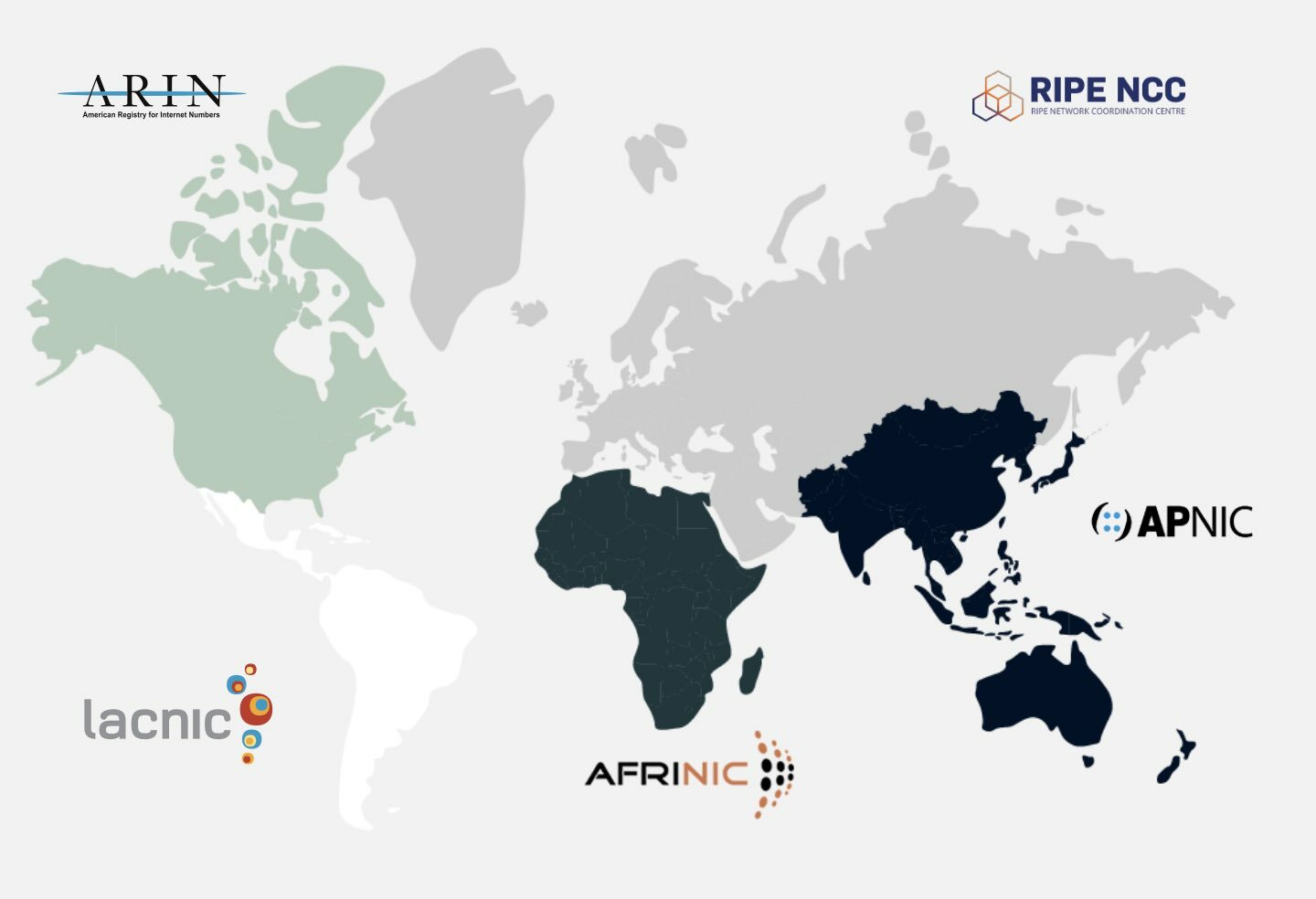
Die große Umverteilung des IP-Adressraums: Warum die IPv4-„Knappheit“
InterLIR GmbH ist eine Marktplatzlösung, die sich zum Ziel gesetzt hat, Netzwerkverfügbarkeitsprobleme
Auch wenn Sie nicht vorhaben, Ihr IPv4-Netzwerk zu verkaufen, gibt es immer noch
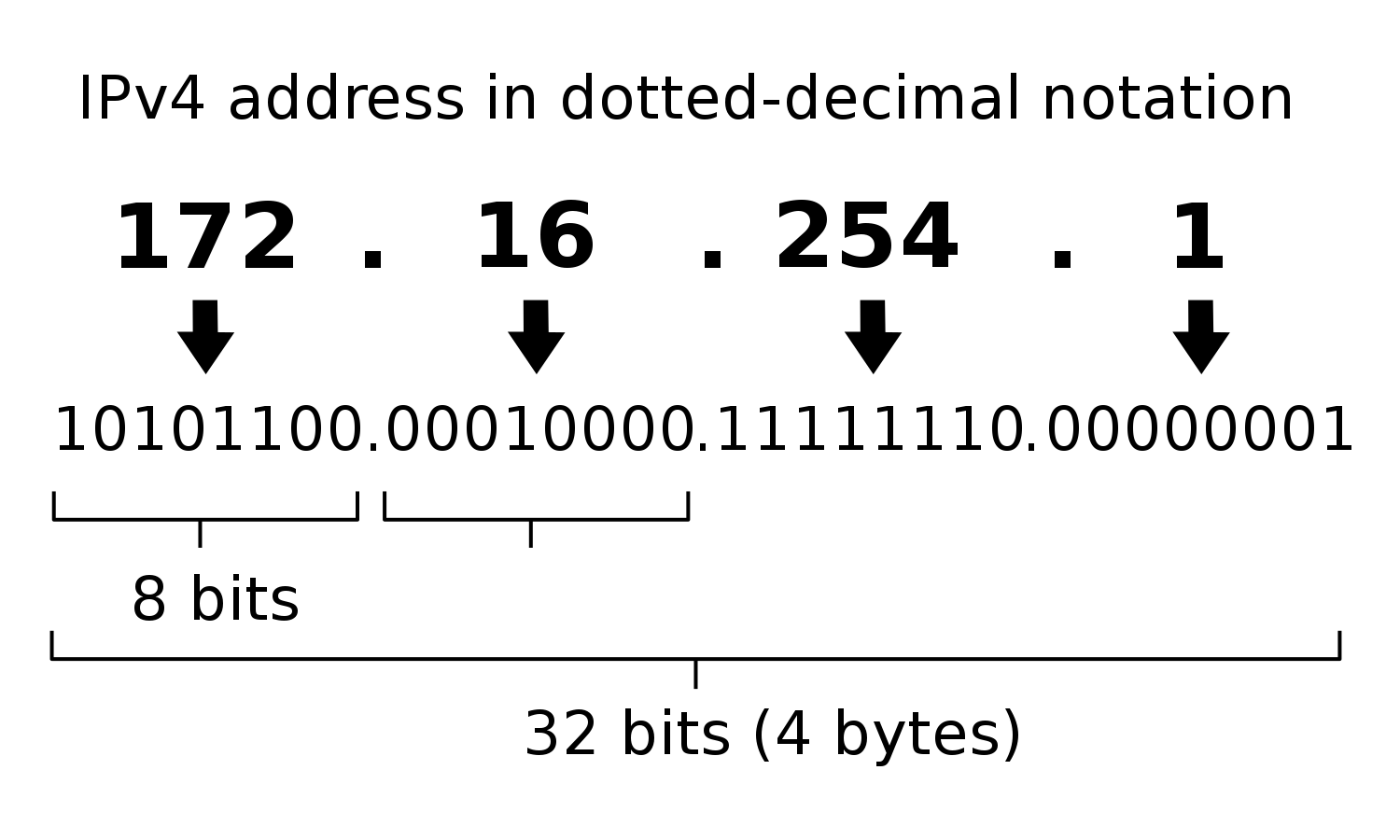
Eine Internet Protocol (IP)-Adresse ist eine eindeutige Kennung, die jedem mit dem
Die steigende Nachfrage nach IP-Blöcken hat die Preise in die Höhe getrieben und
Netzwerk-IP-Adressen variieren und erfordern eine fachkundige Beratung für Netzwerkbetreiber.
Einführung Im heutigen digitalen Umfeld ist der Schutz der Netzwerksicherheit von
In einer Ära, die von digitaler Konnektivität vorangetrieben wird, hat der Wert