Когда 20% интернета погасло: руководство для бизнес-лидеров по пониманию рисков инфраструктуры
Краткое содержание: что нужно знать
🎯 Концентрация критической инфраструктуры: Единственный шестичасовой технический сбой в Cloudflare 18 ноября 2025 года нарушил 20% глобального интернет-трафика, затронув всё — от чат-ботов с ИИ до киосков заказов McDonald’s, обнажив опасную зависимость от ограниченного числа инфраструктурных провайдеров.
💰 Колоссальный экономический ущерб: Простой привёл к совокупным потерям в $5–15 млрд в час для всех пострадавших бизнесов, при этом отдельные компании теряли от $300 000 до $1 млн в час в зависимости от масштаба.
🚀 Необходимость стратегических действий: Руководители должны немедленно провести аудит зависимостей инфраструктуры, внедрить стратегии избыточности с несколькими поставщиками и подготовить «цифровые резервные генераторы» на случай, когда (не если) произойдёт следующий крупный сбой.
⚠️ Урок для фондового рынка: Несмотря на катастрофический операционный сбой, акции Cloudflare упали всего на 2,8% к закрытию, что демонстрирует: инвесторы считают устойчивость инфраструктуры управляемым риском, если компании реагируют прозрачно и принимают конкретные меры предотвращения.
Почему нетехническому руководителю важно учитывать «технические» простои?
Начну с простого сценария, который, вероятно, произошёл в вашей компании 18 ноября 2025 года. Ваша команда маркетинга не могла получить доступ к инструментам дизайна в Canva. Ваша платформа поддержки клиентов перестала работать. Разработчики не могли обратиться к ChatGPT или Claude за помощью в написании кода. Сотрудники не могли запросить отпуск, потому что HR-система была недоступна. А если у вас есть розничные точки, ваши киоски самообслуживания могли показывать страницы с ошибками вместо приёма заказов.
Все эти сбои в совершенно разных компаниях и платформах имели одну общую причину: Cloudflare, незаметная инфраструктурная компания, которая обрабатывает около 20% всего интернет-трафика, столкнулась с катастрофическим техническим сбоем, продолжавшимся почти шесть часов. Представьте Cloudflare как электрическую сеть для современного интернета. Когда сеть отключается, неважно, насколько хорошо спроектировано ваше здание или сколько вы вложили в свои операции — свет просто не включится.
Проще говоря, облачные инфраструктурные провайдеры, такие как Cloudflare, — это цифровые аналоги коммунальных услуг: незаметные до тех пор, пока не выйдут из строя, но абсолютно критичные для бизнес-операций. Они определяют, смогут ли ваши клиенты получить доступ к вашему сайту, будут ли ваши приложения работать корректно и останутся ли ваши цифровые сервисы доступными в ключевые часы работы бизнеса. Когда они падают, ваш бизнес падает вместе с ними, независимо от того, сколько вы вложили в собственные технологии.
То, что делает этот конкретный инцидент переломным моментом, — это не только его масштаб (хотя затронутые сотни миллионов пользователей и ущерб в миллиарды, безусловно, значимы), но и то, что он раскрывает о скрытых рисках архитектуры современных бизнес-операций. Мы сосредоточили такую большую часть нашей цифровой инфраструктуры вокруг небольшого числа провайдеров, что их сбои теперь каскадно распространяются на целые сектора экономики одновременно. Понимание этого риска концентрации и подготовка к нему больше не являются опциональными — это фундаментальное требование для обеспечения непрерывности бизнеса.
В этом руководстве я разберу, что произошло 18 ноября 2025 года, переведу техническую сложность на язык бизнеса, объясню, почему это важно для вашего стратегического планирования, и предоставлю четкий план для защиты вашей организации от подобных сбоев в будущем. Давайте начнем с понимания того, как мы оказались в этой шаткой ситуации.
Как мы стали настолько зависимы от горстки инфраструктурных компаний?
Чтобы понять уязвимость сегодняшней инфраструктуры, мне нужно вернуть вас в ранние дни коммерческого интернета в 1990-х. Представьте интернет как маленький город, где каждый бизнес управлял своими серверами, обеспечивал свою безопасность и обрабатывал свою маршрутизацию трафика. Такой подход работал хорошо, когда было тысячи сайтов, но требовал значительных технических знаний и капиталовложений, которые большинство бизнесов не могли поддерживать.
От отдельных генераторов к единой энергосети
По мере стремительного роста интернета — от тысяч сайтов до миллиардов — произошла естественная консолидация. Компании вроде Cloudflare, Amazon Web Services и Microsoft Azure стали «энергокомпаниями» цифровой эпохи. Они предложили взять на себя всю сложную инфраструктурную работу — безопасность, оптимизацию скорости, маршрутизацию трафика, защиту от DDoS — чтобы бизнес мог сосредоточиться на своих ключевых задачах вместо управления серверами.
Этот переход принёс огромную пользу. Небольшой стартап в сфере электронной коммерции получил доступ к такой же корпоративной инфраструктуре, как у компаний из списка Fortune 500, за малую часть стоимости. Сайты стали загружаться быстрее. Безопасность значительно улучшилась. Технические барьеры для запуска цифрового бизнеса существенно снизились. Это похоже на переход от автономных генераторов у каждого здания к подключению к надёжной энергосети — более эффективно, экономично и в целом стабильнее.
Однако такая консолидация создала новый тип риска, который мы только сейчас начинаем осознавать в полной мере. Когда все подключены к одной сети, её отказ влияет на всех одновременно. Как отмечает эксперт по инфраструктуре Майк Чеппл, двадцать лет назад индивидуальные сбои сервисов были обычным делом — вы могли столкнуться с неделей, когда хотя бы один IT-сервис не работал. Но каждый сбой затрагивал только одну компанию. Сегодня мы добились впечатляющей общей надёжности благодаря консолидации, но создали новый риск: когда один из этих инфраструктурных гигантов даёт сбой, 20% интернета отключаются одновременно.
Цифры говорят сами за себя. Только Cloudflare обрабатывает 81 миллион HTTP-запросов в секунду в обычном режиме. Около 35% компаний из списка Fortune 500 зависят от их сервисов. Примерно 32% из 10 000 самых посещаемых веб-сайтов в мире используют их инфраструктуру. Мы, по сути, разместили значительную часть глобальной цифровой экономики на единой платформе — что прекрасно для эффективности, но пугающе с точки зрения отказоустойчивости.
Что на самом деле произошло 18 ноября 2025 года?
Позвольте мне перевести технический сбой в бизнес-аналогию, чтобы понять, что пошло не так. Представьте, что вы управляете глобальной логистической компанией с 330 распределительными центрами по всему миру. Каждые пять минут ваша центральная штаб-квартира отправляет обновлённые инструкции по доставке во все центры. Обычно эти инструкции имеют приемлемый размер — около 60 страниц указаний.
Конфигурационный файл, который стал слишком большим
Утром 18 ноября благонамеренное изменение настроек безопасности базы данных непреднамеренно привело к тому, что система начала получать данные о доставке из двух источников вместо одного. Внезапно размер этих файлов с инструкциями удвоился, превысив 200 страниц — это больше, чем могут обработать ваши распределительные центры. Система в каждом центре попыталась загрузить эти слишком большие инструкции, превысила свою ёмкость памяти и полностью вышла из строя. Ни один заказ не мог быть обработан. Ни одна поставка не могла быть отправлена. Вся глобальная работа остановилась.
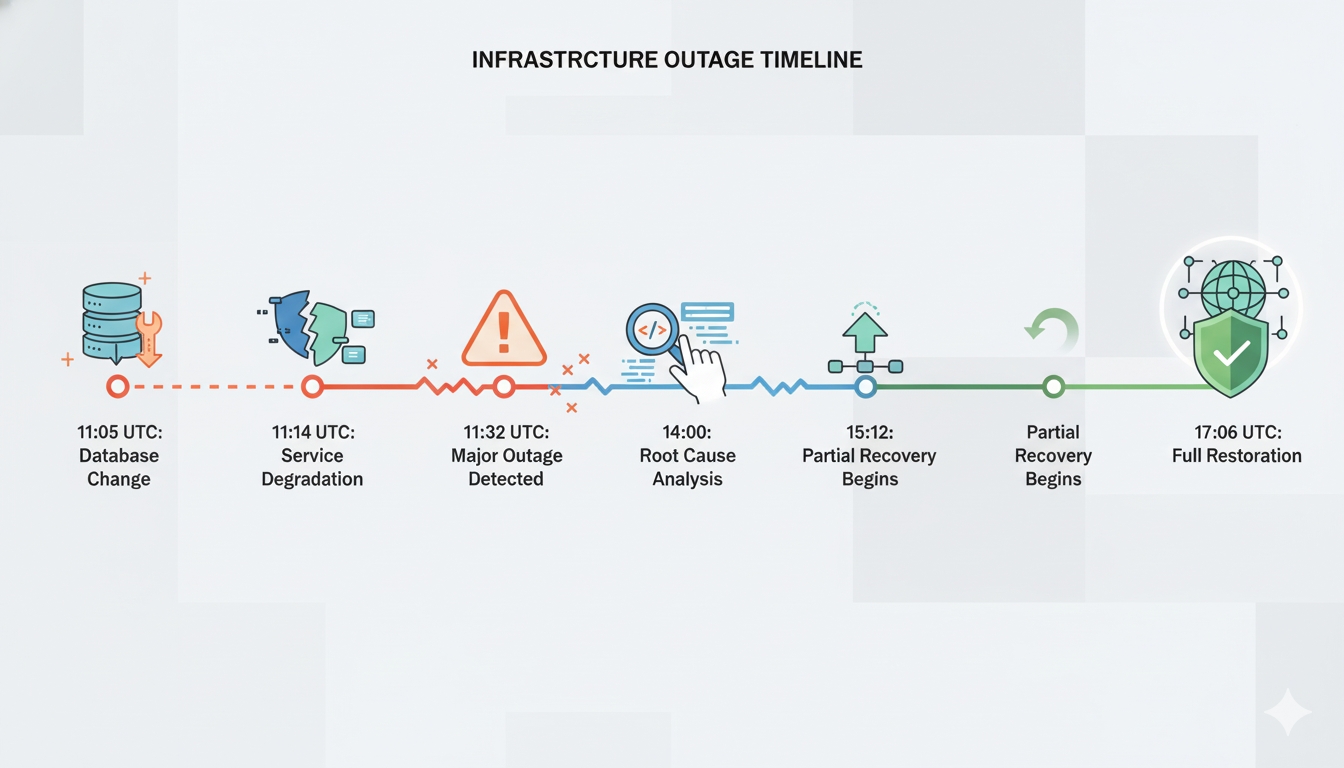
По сути, именно это произошло с Cloudflare. В 11:05 UTC они внесли стандартное изменение прав доступа к базе данных, направленное на повышение безопасности — эквивалент замены замков. Это изменение вызвало непредвиденное последствие: конфигурационный файл, используемый их системой управления ботами, начал получать дублирующиеся данные. Размер файла резко увеличился примерно с 60 характеристик до более чем 200. Этот слишком большой файл автоматически распространился во все 330+ центров обработки данных в течение нескольких секунд благодаря их системе быстрого развертывания.
Почему скорость стала врагом
Именно здесь преимущества эффективности современной инфраструктуры обернулись недостатком. Система развертывания Cloudflare может распространять изменения по всему миру примерно за секунды — впечатляющее инженерное достижение, позволяющее быстро реагировать на угрозы безопасности. Но та же самая скорость означает, что ошибки также мгновенно распространяются по всем дата-центрам до того, как операторы успевают вмешаться. К тому моменту, когда проблема была замечена в 11:31 UTC — всего через 11 минут после появления первых ошибок, — ошибочная конфигурация уже несколько раз разошлась по всему миру.
Диагностику осложнял прерывистый характер сбоя. Сервисы работали пять минут, затем отказывали на пять минут, после чего снова возобновляли работу. Этот чередующийся паттерн имитировал признаки кибератаки, из-за чего команда реагирования на инциденты изначально расследовала неверную причину. Только к 14:24 UTC — более чем через три часа после начала сбоя — удалось выявить первопричину и остановить автоматическую систему от генерации избыточно больших конфигурационных файлов.
Человеческая цена технического сбоя
Масштаб сбоя оказался гораздо шире, чем можно было ожидать от «технической» проблемы. Крупные платформы, такие как X (Twitter), ChatGPT, Spotify, Discord, Zoom и Shopify, одновременно перестали работать. Но наиболее впечатляющими были последствия для физического бизнеса: рестораны McDonald’s не могли принимать заказы через киоски. Детские сады не могли электронно регистрировать приход или уход детей. Транспортные системы лишились табло с информацией в реальном времени. Сотрудники компаний не могли получить доступ к HR-системам для оформления отпусков.
Даже системы мониторинга вышли из строя. DownDetector — сайт, который используют для проверки доступности других сайтов, — сам перестал работать, так как тоже зависел от Cloudflare. Это создало сюрреалистичную ситуацию, когда у пользователей не было надежного способа подтвердить, являются ли их проблемы локальными или частью масштабного сбоя, что усилило неразбериху и беспокойство в соцсетях.
Какова истинная бизнес-стоимость зависимости от инфраструктуры?
Когда я обсуждаю этот инцидент с руководителями компаний, первый вопрос всегда звучит так: «Во сколько это реально обошлось?» Ответ показывает, почему отказоустойчивость инфраструктуры должна быть вопросом уровня совета директоров, а не только ИТ-отдела.
Скрытый мультипликативный эффект одновременного отказа
Исследования затрат из-за простоев показывают, что 93% крупных предприятий сталкиваются с потерями, превышающими $300 000 в час, а 48% сообщают о потерях свыше $1 млн в час. Однако эти цифры отражают простои отдельных компаний. Когда тысячи компаний отключаются одновременно, экономический эффект не складывается — он умножается.
По оценкам аналитиков, совокупный экономический ущерб составляет от $5 до $15 млрд в час для всех затронутых предприятий. За шесть часов это приводит к потенциальным общим потерям в сотни миллионов или даже миллиарды долларов. Разберём, из чего складываются эти затраты:
💸 Прямые потери выручки: Платформы электронной коммерции не могли обрабатывать транзакции в часы пиковых покупок в разных часовых поясах — каждая минута простоя означает упущенные продажи, которые уже не восстановить.
📉 Потери на маркетинге: Компании, запустившие рекламные кампании, продолжали платить за клики и показы, которые приводили на страницы с ошибками вместо рабочих сайтов — сжигая маркетинговые бюджеты без какой-либо отдачи.
🔥 Ущерб репутации: Исследования показывают, что 88% пользователей с меньшей вероятностью вернутся на сайт после негативного опыта, даже если они понимают, что причиной стал сбой у третьей стороны, не подконтрольной компании.
⚖️ Штрафные санкции: Соглашения об уровне обслуживания (SLA) с клиентами активировали штрафные условия и обязательные компенсации за несоблюдение гарантий доступности.
👥 Коллапс продуктивности: Сотни миллионов офисных сотрудников по всему миру потеряли доступ к важным инструментам, многие вообще не могли выполнять свою работу в течение этого времени.
📞 Взрывной рост затрат на поддержку: Службы поддержки клиентов были перегружены запросами от пользователей, не осознававших масштаб проблемы, что отвлекало ресурсы от нормальной работы.
Сектор форекс-трейдинга: Детальный кейс
Для конкретики рассмотрим влияние на форекс-брокеров и брокеров CFD. Эти платформы обеспечивают торговый оборот примерно в $1,58 млрд каждые три часа в обычных условиях. Во время сбоя Cloudflare несколько брокеров, включая Monaxa, Skilling, Xtrade и FXPro, столкнулись с полным параличом операционной деятельности. Трейдеры не могли получить доступ к своим позициям, не могли исполнять сделки и не могли реагировать на движения рынка. Весь торговый оборот за эти три часа — примерно 1% от их обычного месячного объема — просто испарился.
Аналогично, криптовалютные биржи сообщили о значительном снижении торговых объемов в пиковый период сбоя. Активность на рынке NFT сократилась почти до нуля. Некоторые Layer 2-сети блокчейна, полагающиеся на Cloudflare для API-подключений, стали полностью недоступны, что подчеркивает иронию: «децентрализованные» приложения часто зависят от централизованной инфраструктуры.
Почему «это не наша вина» не защитит ваш бизнес
Вот неудобная правда, которая не дает мне покоя как консультанту: клиентам не важно, чья это была вина — им важно, что ваш сервис не работал, когда он был нужен. Когда ваш сайт показывает страницу ошибки Cloudflare вместо загрузки, удар по репутации получает ваш бренд, даже если технический сбой произошел в инфраструктуре, которую вы не контролируете.
Вот почему рассматривать поставщиков инфраструктуры как «чью-то еще проблему» — это стратегическая ошибка. Их надежность напрямую влияет на взаимодействие с клиентами, вашу выручку и конкурентные позиции. Относиться к этому как к чисто техническому вопросу, а не как к бизнес-риску — все равно что считать фундамент здания не своей заботой, потому что вы не инженер-строитель, пока однажды он не треснет и все, что над ним, не обрушится.
Что умные руководители должны делать иначе в будущем?
Сбой Cloudflare в ноябре 2025 года дает несколько четких уроков для бизнес-лидеров, которые стратегически думают о надежности инфраструктуры. Позвольте перевести это в практический план действий.
Понимание трех мегатрендов, формирующих инфраструктурные риски
Прежде чем перейти к конкретным рекомендациям, необходимо понять три силы, которые одновременно делают зависимость от инфраструктуры как более ценной, так и более опасной:
🔮 Ускорение консолидации: Рынок инфраструктуры продолжает консолидироваться вокруг трёх основных провайдеров — Cloudflare, Amazon Web Services и Microsoft Azure, в то время как более мелкие игроки борются за конкуренцию по масштабу и экономической эффективности.
🔧 Двусторонняя автоматизация: Системы быстрого развёртывания, способные распространять изменения глобально за секунды, ускоряют внедрение инноваций и реагирование на угрозы, но также означают мгновенное распространение ошибок до возможности человеческого вмешательства.
📈 Углубление зависимостей: Современные приложения всё чаще полагаются на десятки взаимосвязанных сервисов, создавая цепочки зависимостей, где сбой в одном звене может непредсказуемо распространиться по всей системе.
Фреймворк «Цифровой резервный генератор»
Бетси Купер, основатель и директор Aspen Policy Academy, привела убедительную аналогию при анализе этого сбоя: «Нам нужен цифровой аналог резервных генераторов». Подобно тому, как больницы и дата-центры содержат резервные системы питания на случай отключения электричества, бизнесу необходимы избыточные инфраструктурные возможности на случай сбоев у основных облачных провайдеров.
Что это означает на практике? Это не означает дублирование всей инфраструктуры — это слишком дорого и сложно. Речь идёт о стратегической избыточности для критически важных сервисов и возможностях быстрого переключения при отказе основных систем.
90-дневный план действий для руководителя
Вот конкретный план по повышению устойчивости инфраструктуры в следующем квартале:
1️⃣ Проведите аудит зависимостей (Недели 1-2): Составьте карту всех критически важных бизнес-сервисов и определите, от каких поставщиков инфраструктуры они зависят, включая косвенные зависимости через ваших поставщиков программного обеспечения. Создайте визуальную «карту зависимостей», отображающую единые точки отказа. Спросите свою техническую команду: «Если Cloudflare/AWS/Azure будут недоступны шесть часов сегодня, какие из наших сервисов выйдут из строя?»
2️⃣ Оцените свои риски (Недели 3-4): Количественно определите влияние простоев инфраструктуры на бизнес, оценив почасовые потери выручки, затраты на простои и штрафы за нарушение SLA для каждого критически важного сервиса. Это становится обоснованием для инвестиций в отказоустойчивость. Будьте реалистами — предполагайте, что сбои будут происходить в часы пиковой нагрузки, а не в удобное время в 3 часа ночи в воскресенье.
3️⃣ Внедрите стратегию использования нескольких поставщиков для критических сервисов (недели 5-8): Для ваших наиболее важных сервисов внедрите подходы с использованием нескольких CDN на основе DNS-балансировки нагрузки и автоматического переключения при отказе. Это не означает отказ от основного провайдера — это означает наличие проверенного резервного решения, которое автоматически активируется при отказе основного. Расставьте приоритеты на основе влияния на бизнес, а не технической сложности.
4️⃣ Настройте независимый мониторинг (Недели 9-10): Убедитесь, что ваша инфраструктура мониторинга не зависит от отслеживаемых сервисов. Используйте несколько провайдеров мониторинга в разных дата-центрах, чтобы оперативно выявлять сбои и различать проблемы в вашей системе и у провайдера инфраструктуры.
5️⃣ Проверьте свои планы резервного копирования (Недели 11-12): Реально протестируйте процедуры переключения при отказе в реалистичных условиях, а не просто задокументируйте их. Запланируйте «учебную тревогу», в ходе которой вы намеренно переключитесь на резервную инфраструктуру и проверите, что всё работает. Большинство планов аварийного восстановления выглядят отлично на бумаге, но проваливаются при первом реальном испытании.
6️⃣ Выделяйте бюджет на качество, а не на цену (Постоянно): Самый дешевый вариант инфраструктуры редко оказывается наиболее выгодным с учетом затрат на простои. Выделяйте ресурсы на обеспечение надежности, избыточности и проверенных методов реагирования на инциденты, а не на оптимизацию исключительно по ежемесячным затратам.
Контраргумент: почему акции Cloudflare выглядят привлекательно
Вот что может вас удивить: несмотря на этот катастрофический сбой, я утверждаю, что акции Cloudflare представляют собой разумную инвестицию на текущих уровнях около $196, снизившись с цены $202 до сбоя. Почему? Потому что рыночная реакция говорит нам кое-что важное о том, как инвесторы оценивают инфраструктурные риски.
Акции Cloudflare упали на 7,0% в худший момент 18 ноября, но закрылись всего на 2,8% ниже после прозрачной коммуникации компании и быстрого восстановления сервиса. Эта относительно сдержанная реакция — по сравнению с утечками данных, которые могут вызвать падение на 20-30%, — говорит о том, что инвесторы рассматривают это как восстановимый операционный инцидент, а не фундаментальный провал компании.
Что еще важнее, базовые финансовые показатели остаются сильными. Выручка за 3-й квартал 2025 года выросла на 31% в годовом выражении до $562 млн, а чистые убытки значительно сократились с $15,3 млн до всего $1,3 млн, демонстрируя явное движение к прибыльности. Поскольку большинство аналитиков сохраняют рейтинги «Покупать», рынок фактически говорит: «Они напортачили, признали это, исправляют ситуацию, и долгосрочная история роста остается неизменной».
Для руководителей компаний это демонстрирует ценный урок о реагировании на кризисы: прозрачность, быстрое устранение последствий и конкретные меры по предотвращению могут ограничить репутационный ущерб даже после серьезных операционных сбоев. Решение генерального директора Мэтью Принса лично опубликовать детальный технический разбор в течение 12 часов — включая фактический код, вызвавший сбой — продемонстрировало ту подотчетность, которая быстро восстанавливает доверие.
Сбой Cloudflare 18 ноября 2025 года был не просто техническим сбоем — это был сигнал тревоги о скрытой архитектуре современных бизнес-процессов. Мы построили нашу цифровую экономику на основе концентрированной инфраструктуры, которая обеспечивает выдающуюся эффективность и производительность в нормальных условиях, но создает системные риски в сценариях сбоев.
Перед бизнес-лидерами стоит вопрос не о том, произойдут ли подобные сбои снова — в системах такой сложности и масштаба они неизбежны — а о том, будет ли ваша организация готова, когда они произойдут. Компании, которые выйдут из следующего крупного сбоя инфраструктуры сильнее всего, — это те, кто инвестировал в стратегическое резервирование, поддерживал независимый мониторинг, тестировал резервные процедуры и относился к устойчивости инфраструктуры как к вопросу уровня совета директоров, а не как к второстепенной ИТ-задаче.
Как метко заметил один пользователь Reddit во время сбоя, интернет по-прежнему «держится на скотче и молитвах». Задача для нынешнего поколения бизнес-лидеров — превратить этот скотч в инженерную устойчивость, сохраняя при этом скорость, инновации и доступность, которые сделали современный интернет революционным. Стоимость этой трансформации измеряется миллионами. Стоимость ее игнорирования, как мы узнали 18 ноября, измеряется миллиардами.