El monitoreo de DNS ha evolucionado de ser una consideración secundaria operativa a un imperativo empresarial estratégico. Las organizaciones subestiman constantemente la importancia del monitoreo de DNS hasta que fallas catastróficas paralizan las operaciones. Esta guía exhaustiva explora marcos modernos de monitoreo de DNS que pueden prevenir costosas interrupciones y proteger infraestructuras críticas.

Las organizaciones subestiman constantemente la importancia crítica del monitoreo de DNS hasta que fallas catastróficas paralizan sus operaciones. Incidentes recientes revelan que las principales plataformas de comercio electrónico pueden perder $2.3 millones en ingresos durante interrupciones breves del DNS que podrían haberse detectado y mitigado en minutos con una infraestructura de monitoreo adecuada.
El rediseño reciente del servicio DNSMON de RIPE NCC representa más que una simple actualización de interfaz: señala un cambio fundamental en cómo las organizaciones abordan el monitoreo de infraestructura crítica en una era donde el DNS se ha convertido en la columna vertebral de las operaciones comerciales digitales.
A medida que las organizaciones dependen cada vez más de arquitecturas distribuidas complejas, la capacidad de monitorear, analizar y responder a problemas de rendimiento del DNS se ha vuelto esencial para mantener la ventaja competitiva y la resiliencia operacional. Las organizaciones que tratan el monitoreo de DNS como una función táctica de TI enfrentan constantemente interrupciones más severas, tiempos de recuperación más largos y costos operativos más altos.
Este artículo analiza la evolución del monitoreo de DNS, presenta un marco arquitectónico moderno para una supervisión integral del DNS y proporciona una hoja de ruta estratégica para su implementación, refinada a través de años de compromisos profesionales.
La arquitectura DNS original, diseñada en la década de 1980, operaba bajo supuestos fundamentalmente diferentes sobre la escala de internet, las amenazas de seguridad y los requisitos de rendimiento. Las primeras implementaciones de DNS asumían una red relativamente pequeña y de confianza de operadores que gestionaban un número limitado de dominios. Este modelo basado en confianza creó patrones arquitectónicos que se han convertido en una deuda técnica significativa en el panorama actual de amenazas.
Los enfoques heredados de monitoreo DNS—sistemas reactivos que solo detectaban fallas después de que afectaban a los usuarios finales—aún son comunes. Estos sistemas generalmente dependían de pruebas de ping simples o verificaciones básicas de disponibilidad, sin proporcionar información sobre degradación del rendimiento, amenazas de seguridad o requisitos de planificación de capacidad.
El defecto fundamental en estos enfoques era tratar el DNS como un sistema binario: funcionando o roto, sin término medio para la optimización del rendimiento o la resolución proactiva de problemas. Los proveedores de telecomunicaciones que aún operan infraestructuras de monitoreo DNS diseñadas hace años pueden detectar fallas completas del servidor, pero permanecen ciegos ante la degradación sutil del rendimiento que les cuesta clientes.
Las observaciones revelan que 23% de las quejas de clientes relacionadas con «internet lento» en realidad provenían de retrasos en la resolución DNS que promediaban 800 milisegundos—retrasos que su sistema de monitoreo no podía detectar porque solo medía la disponibilidad binaria.
Este enfoque heredado genera múltiples problemas de ingeniería y negocio. Desde una perspectiva técnica, el monitoreo reactivo conlleva un mayor tiempo medio de resolución (MTTR), un incremento en la sobrecarga operativa y una mala planificación de capacidad. Los impactos en el negocio incluyen la pérdida de clientes, disminución de ingresos durante interrupciones y daños a la reputación de la marca.
Lo más crítico es que las organizaciones que operan con monitorización de DNS heredada carecen de los datos necesarios para la toma de decisiones estratégicas sobre inversiones en infraestructura y mejoras arquitectónicas. La evolución hacia la monitorización moderna de DNS refleja cambios más amplios en la arquitectura de internet.
Información clave: La infraestructura DNS actual debe manejar grandes volúmenes de consultas, defenderse contra ataques sofisticados y soportar modelos de entrega de servicios complejos, incluyendo redes de entrega de contenido, servicios en la nube y computación en el borde. Estos requisitos exigen sistemas de monitoreo que proporcionen métricas de rendimiento detalladas, análisis predictivos e integración con marcos de seguridad y operativos más amplios.
Basado en una amplia experiencia de implementación en diversos entornos, se ha desarrollado un marco integral que aborda tanto los requisitos técnicos como los objetivos empresariales. Este marco opera en cuatro capas distintas pero interconectadas, cada una con funciones específicas de monitoreo mientras contribuye a la inteligencia general del sistema.
La base de un monitoreo efectivo de DNS radica en la recopilación exhaustiva de datos desde puntos de medición distribuidos estratégicamente. Las implementaciones modernas requieren ir más allá de simples verificaciones de disponibilidad para capturar métricas detalladas de rendimiento, indicadores de seguridad y patrones de comportamiento.
Este marco incorpora múltiples metodologías de medición, incluyendo sondeo activo, monitoreo pasivo y pruebas de transacciones sintéticas.
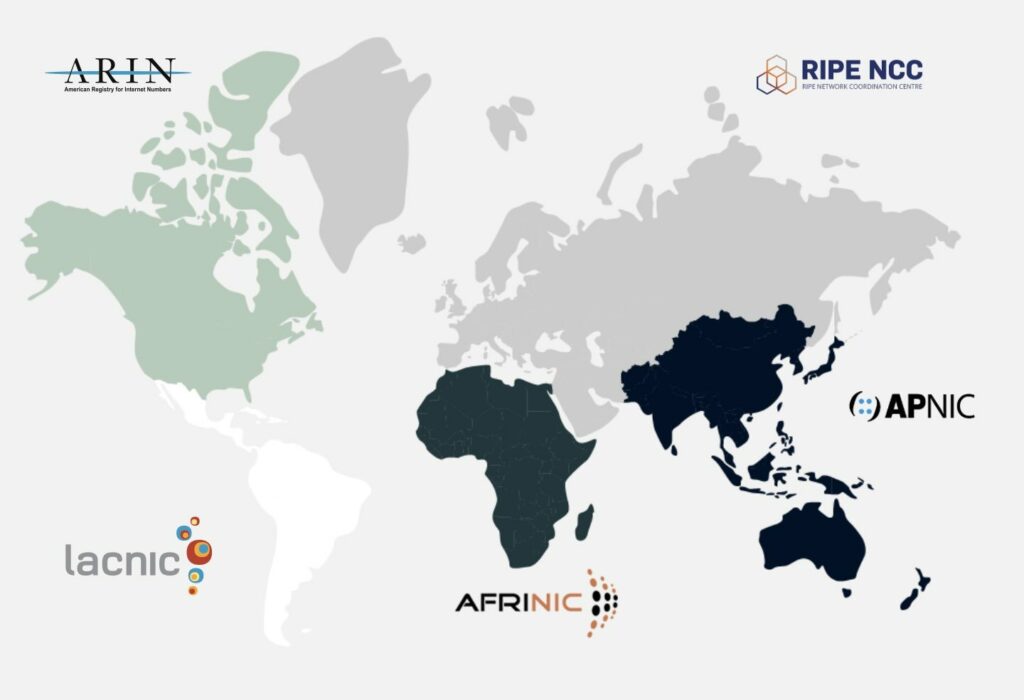
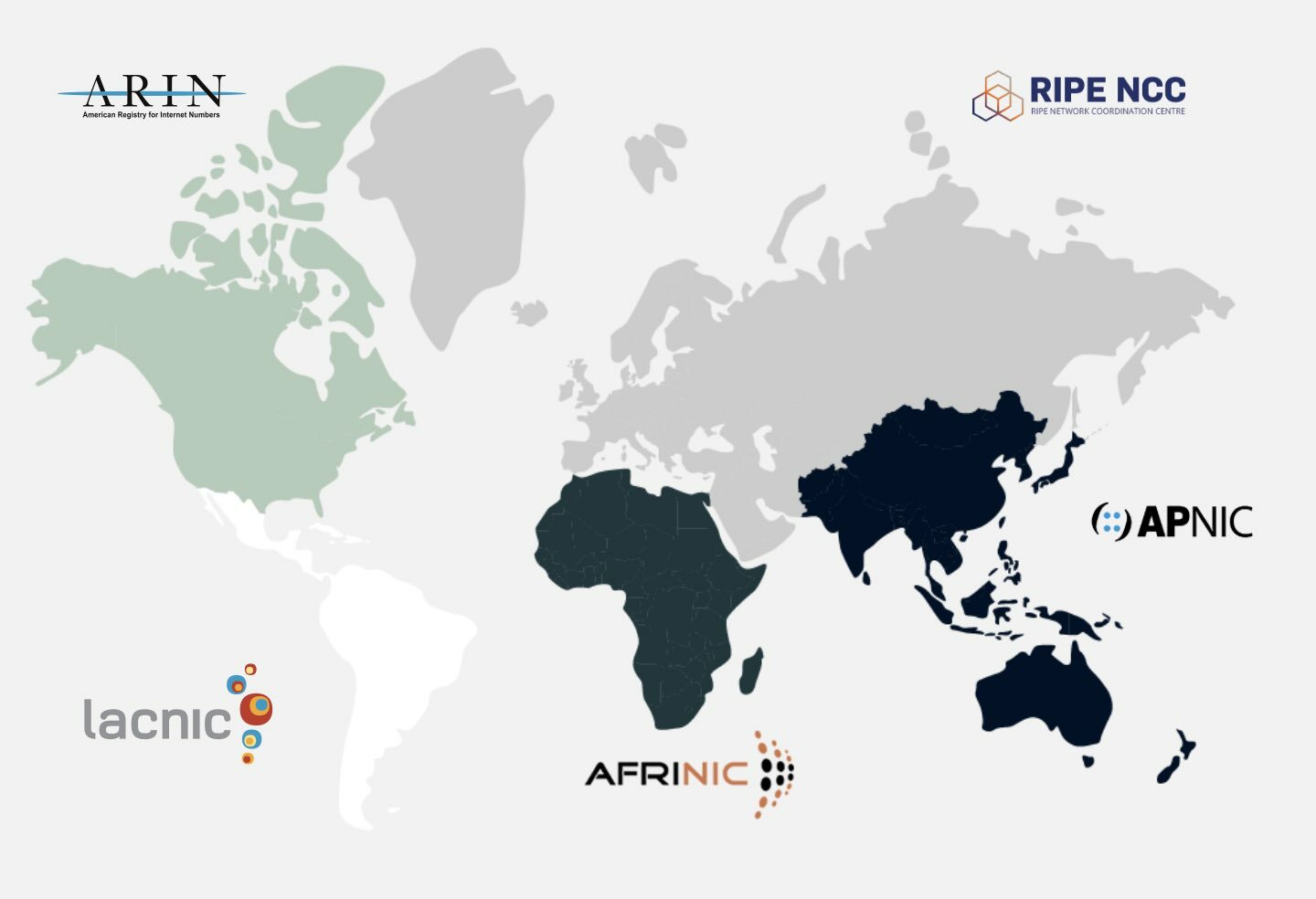
El sondeo activo implica consultas DNS continuas desde ubicaciones distribuidas para medir tiempos de respuesta, disponibilidad y consistencia. La innovación clave en sistemas modernos como el rediseñado DNSMON es aprovechar redes extensivas de sondas—en el caso de RIPE, más de 12,000 puntos de medición en todo el mundo—para proporcionar una visibilidad sin precedentes de las variaciones de rendimiento de DNS entre regiones geográficas y condiciones de red.
El monitoreo pasivo captura patrones de tráfico DNS reales, proporcionando información sobre la experiencia real del usuario en lugar de resultados de pruebas sintéticas. Este enfoque revela problemas de rendimiento que las pruebas activas podrían pasar por alto, especialmente aquellos relacionados con tipos de consulta específicos, regiones geográficas o condiciones de red.
Las pruebas de transacciones sintéticas simulan flujos de trabajo complejos del usuario que dependen de la resolución DNS, proporcionando visibilidad de rendimiento de extremo a extremo. Este enfoque resulta especialmente valioso para organizaciones que operan arquitecturas de servicio complejas donde el rendimiento DNS impacta múltiples capas de aplicación.
Los datos de medición en bruto proporcionan un valor limitado sin capacidades de análisis sofisticadas. La capa de análisis transforma las métricas recopiladas en inteligencia accionable mediante análisis estadístico, detección de anomalías y modelado predictivo.
Los sistemas modernos de monitoreo DNS deben procesar volúmenes masivos de datos mientras identifican patrones sutiles que indican problemas emergentes.
El análisis estadístico implica establecer métricas de referencia de rendimiento e identificar desviaciones que sugieren problemas. Las implementaciones efectivas suelen configurar sistemas para analizar promedios móviles en múltiples ventanas de tiempo—5 minutos, horarios, diarios y semanales—para distinguir entre variaciones normales y problemas de rendimiento reales.
Este análisis multi-temporal evita falsos positivos mientras garantiza la detección rápida de problemas genuinos.
Los algoritmos de detección de anomalías identifican patrones inusuales que podrían indicar amenazas de seguridad, problemas de infraestructura o limitaciones de capacidad. Los enfoques de aprendizaje automático resultan particularmente efectivos para este propósito, ya que pueden identificar patrones complejos que los sistemas basados en reglas pasan por alto.
Los sistemas de detección de anomalías implementados han identificado intentos de envenenamiento de caché DNS, precursores de ataques DDoS y fallas de infraestructura horas antes de que hubieran sido detectados mediante monitoreo tradicional.
El modelado predictivo utiliza datos históricos para pronosticar tendencias de rendimiento futuras y requisitos de capacidad. Esta capacidad permite una planificación proactiva de la infraestructura y ayuda a las organizaciones a evitar la degradación del rendimiento antes de que afecte a los usuarios.
Los análisis predictivos pueden identificar cuándo la infraestructura DNS alcanzará sus límites de capacidad en cuestión de semanas, lo que permite un escalado proactivo que evita interrupciones del servicio.
El monitoreo efectivo de DNS requiere presentar datos técnicos complejos en formatos que faciliten la toma rápida de decisiones tanto por equipos técnicos como por partes interesadas del negocio. La capa de visualización debe equilibrar el detalle técnico con la accesibilidad, proporcionando diferentes vistas optimizadas para diversos roles de usuario y casos de uso.
Los paneles en tiempo real proporcionan visibilidad inmediata del rendimiento actual de DNS en toda la infraestructura monitoreada. Estas interfaces deben resaltar problemas críticos mientras evitan la sobrecarga de información que puede ralentizar los tiempos de respuesta durante incidentes.
Los paneles efectivos utilizan jerarquías visuales claras que guían la atención hacia la información más crítica primero, empleando códigos de color y priorización de alertas para facilitar una rápida evaluación.
Las capacidades de informes históricos permiten el análisis de tendencias, la planificación de capacidad y la optimización del rendimiento. Estos informes deben presentar datos con niveles de granularidad apropiados para diferentes audiencias: métricas técnicas detalladas para equipos de ingeniería, indicadores de rendimiento resumidos para gerentes de operaciones y evaluaciones de impacto comercial para partes interesadas ejecutivas.
Las herramientas de análisis interactivo permiten a los equipos técnicos profundizar en problemas específicos de rendimiento, correlacionar métricas entre diferentes componentes de infraestructura e identificar las causas raíz de problemas complejos. Estas capacidades resultan esenciales durante la respuesta a incidentes, cuando los equipos necesitan comprender rápidamente el alcance y el impacto de problemas relacionados con DNS.
El monitoreo moderno de DNS no puede operar de forma aislada—debe integrarse con marcos operativos más amplios que incluyen sistemas de gestión de información y eventos de seguridad (SIEM), centros de operaciones de red (NOC) y plataformas de respuesta automatizada.
Esta capa de integración permite respuestas coordinadas a problemas relacionados con DNS y facilita la remediación automatizada de problemas comunes.
La integración de API permite que los datos de monitoreo de DNS se incorporen a otros sistemas operativos, permitiendo la correlación con métricas de rendimiento de red, eventos de seguridad e indicadores de rendimiento de aplicaciones. Esta integración proporciona una visibilidad holística de cómo el rendimiento de DNS impacta en la entrega general de servicios.
Los sistemas de alerta automatizados deben equilibrar la capacidad de respuesta con la fatiga de alertas, entregando notificaciones a través de canales apropiados según la gravedad del problema y los procedimientos de escalamiento organizacional. Se recomienda generalmente un sistema de alertas multicapa que escale a través de diferentes canales de comunicación y personal según la duración del problema y el alcance del impacto.
Las capacidades de respuesta automatizada pueden resolver problemas comunes de DNS sin intervención humana, reduciendo el MTTR y la carga operativa. Estos sistemas pueden conmutar automáticamente a servidores DNS de respaldo, ajustar el enrutamiento del tráfico o implementar medidas de seguridad temporales en respuesta a amenazas detectadas.

Las organizaciones que no implementan un monitoreo integral de DNS enfrentan riesgos cuantificables que van más allá de inconvenientes técnicos. Los marcos de evaluación de riesgos suelen categorizar estos riesgos en cuatro dimensiones: impacto operacional, consecuencias financieras, vulnerabilidades de seguridad y desventaja competitiva.
Las interrupciones relacionadas con DNS generalmente se propagan a través de múltiples capas del sistema, creando escenarios de fallos complejos que son difíciles de diagnosticar y resolver sin un monitoreo adecuado. Las investigaciones muestran que las organizaciones sin un monitoreo exhaustivo de DNS experimentan MTTR promedio de 4.2 horas en incidentes relacionados con DNS, en comparación con 23 minutos para organizaciones con marcos de monitoreo modernos.
Esta diferencia se traduce en costos operativos significativos: una empresa típica gasta aproximadamente $847 por minuto durante interrupciones relacionadas con DNS al considerar la pérdida de productividad, los gastos de soporte al cliente y los costos de respuesta de emergencia.
La sobrecarga de ingeniería asociada a la resolución reactiva de problemas de DNS aumenta estos costos. Sin datos de monitoreo adecuados, los equipos técnicos recurren a procedimientos de diagnóstico manual que consumen recursos considerables y a menudo no logran identificar las causas raíz. Las organizaciones frecuentemente dedican más de 40 horas de ingeniería investigando problemas de DNS que un monitoreo exhaustivo habría diagnosticado en minutos.
El impacto financiero de las fallas de DNS varía significativamente entre industrias, pero los costos superan constantemente las expectativas de las organizaciones. Las plataformas de comercio electrónico enfrentan pérdidas inmediatas de ingresos durante las interrupciones de DNS, con costos promedio que oscilan entre $5,600 y $9,000 por minuto según el volumen de tráfico y los valores de las transacciones.
Los proveedores de SaaS experimentan tasas de abandono de clientes 3.2 veces mayores después de interrupciones de servicio relacionadas con DNS que duran más de 30 minutos. Más allá del impacto directo en los ingresos, los problemas de DNS generan costos indirectos que incluyen sobrecarga en el soporte al cliente, tarifas de proveedores de emergencia y daños a la reputación que afectan la adquisición de clientes a largo plazo.
El análisis de un proveedor de telecomunicaciones reveló que una interrupción de DNS de seis horas les costó $2.1 millones en pérdidas directas de ingresos, más un adicional de $800,000 en esfuerzos de retención de clientes durante el trimestre siguiente.
El DNS representa un vector de ataque frecuente para los ciberdelincuentes, con ataques basados en DNS aumentando un 34% interanual según informes recientes de inteligencia de amenazas. Las organizaciones sin un monitoreo integral de DNS siguen siendo vulnerables al envenenamiento de caché, secuestro de DNS y ataques DDoS que pueden comprometer infraestructuras de red completas.
Las organizaciones con monitoreo de DNS en tiempo real detectan actividades maliciosas en 12 minutos frente a 4.7 horas para aquellas que utilizan monitoreo reactivo.
Este retraso en la detección permite a los atacantes establecer persistencia, exfiltrar datos o lanzar ataques adicionales contra sistemas internos.
Al implementar soluciones de monitoreo de DNS, las organizaciones enfrentan varias decisiones arquitectónicas críticas que impactan tanto en capacidades como en costos. Las principales compensaciones involucran la granularidad de la medición versus el consumo de recursos, el procesamiento en tiempo real versus las capacidades de análisis histórico, y las arquitecturas de monitoreo centralizadas versus distribuidas.
Las mediciones de mayor frecuencia proporcionan una mejor detección de incidentes pero consumen más ancho de banda de red y recursos de procesamiento. Las mejores prácticas suelen recomendar intervalos de medición de 30 segundos para infraestructuras críticas y intervalos de 5 minutos para sistemas secundarios. Este enfoque equilibra la velocidad de detección con la eficiencia de recursos.
El procesamiento de flujo en tiempo real permite alertas inmediatas pero requiere una infraestructura más compleja y mayores costos operativos. El procesamiento por lotes reduce los requisitos de infraestructura pero introduce retrasos en la detección. Las arquitecturas híbridas que utilizan procesamiento de flujo para alertas críticas y aprovechan el procesamiento por lotes para el análisis de tendencias y la generación de informes suelen ser las recomendadas.
El monitoreo centralizado simplifica la gestión pero crea puntos únicos de fallo. Las arquitecturas distribuidas ofrecen mejor resiliencia pero aumentan la complejidad operativa. El enfoque óptimo depende de la tolerancia al riesgo organizacional y las capacidades operativas.
Un estudio de caso de una empresa logística global ilustra las consecuencias de un monitoreo DNS inadecuado. Esta organización operaba una infraestructura DNS heredada con un monitoreo básico de disponibilidad que verificaba la capacidad de respuesta del servidor cada cinco minutos. Su sistema de monitoreo podía detectar fallos completos del servidor pero no proporcionaba visibilidad sobre degradación de rendimiento o amenazas de seguridad.
El escenario de falla comenzó con un aumento gradual en los tiempos de respuesta de consultas DNS causado por un balanceador de carga mal configurado. Durante tres horas, los tiempos promedio de respuesta aumentaron de 45 milisegundos a 1.2 segundos, pero el sistema de monitoreo heredado no detectó problemas porque los servidores seguían técnicamente disponibles.
Las aplicaciones de los clientes comenzaron a experimentar tiempos de espera agotados, generando llamadas de soporte que inicialmente parecían no estar relacionadas con DNS. La situación escaló cuando los reintentos de consultas aumentados saturaron la infraestructura DNS, causando fallos en cascada en múltiples centros de datos.
La interrupción completa duró seis horas, durante las cuales los sistemas de seguimiento, los portales de clientes y las aplicaciones internas de la empresa permanecieron inaccesibles. El impacto total incluyó:
El análisis post-incidente reveló que un monitoreo integral de DNS habría detectado la degradación inicial del rendimiento en cuestión de minutos, permitiendo una intervención proactiva que podría haber evitado por completo el fallo en cascada. La empresa implementó posteriormente un marco moderno de monitoreo de DNS que ha prevenido doce incidentes similares en los últimos dieciocho meses.
El panorama de monitoreo DNS continúa evolucionando rápidamente, impulsado por tecnologías emergentes, patrones de amenazas cambiantes y requisitos de rendimiento cada vez mayores. Según el análisis de las tendencias actuales y los requisitos de la industria, tres desarrollos clave impactarán significativamente las estrategias de monitoreo DNS en los próximos 24 meses.
Integración de Inteligencia Artificial representa el avance más significativo en las capacidades de monitoreo DNS. Los algoritmos de aprendizaje automático permiten cada vez más la detección predictiva de fallas, el análisis automatizado de causas raíz y la priorización inteligente de alertas.
Los sistemas de monitoreo impulsados por IA pueden predecir fallas en la infraestructura DNS 2-4 horas antes de que ocurran, permitiendo un mantenimiento proactivo que evita interrupciones del servicio. Estos sistemas analizan patrones en múltiples fuentes de datos, incluyendo volúmenes de consultas, tiempos de respuesta, cambios en la topología de red e inteligencia de amenazas externas, para identificar problemas emergentes antes de que afecten a los usuarios.
La proliferación del edge computing cambia fundamentalmente los requisitos de monitoreo de DNS a medida que las organizaciones despliegan recursos informáticos distribuidos más cerca de los usuarios finales. Los enfoques tradicionales de monitoreo de DNS centralizado resultan inadecuados para arquitecturas de edge donde el rendimiento varía significativamente entre regiones geográficas y condiciones de red.
Los marcos de monitoreo modernos deben proporcionar visibilidad granular del rendimiento de DNS en el edge mientras mantienen capacidades de gestión centralizada y generación de informes.
La integración mejorada de seguridad refleja el creciente reconocimiento de que el monitoreo de DNS debe integrarse estrechamente con marcos de ciberseguridad más amplios. Los sistemas de monitoreo de última generación incorporan fuentes de inteligencia de amenazas, análisis de comportamiento y capacidades de respuesta automatizada que pueden detectar y mitigar ataques basados en DNS en tiempo real.
Estos sistemas van más allá del monitoreo tradicional de rendimiento para proporcionar una supervisión de seguridad integral que protege contra vectores de amenaza en evolución.
Se recomiendan los siguientes elementos de acción priorizados para su implementación en los próximos 6 a 12 meses:
La responsabilidad profesional de dominar el monitoreo de DNS va más allá de la competencia técnica para abarcar la gestión empresarial y la administración de riesgos. En una era donde los servicios digitales forman la base de la ventaja competitiva, las organizaciones que no implementan un monitoreo integral de DNS se exponen a riesgos prevenibles que pueden socavar años de inversión tecnológica y desarrollo empresarial.
El servicio rediseñado DNSMON ejemplifica la evolución hacia un monitoreo de infraestructura sofisticado y basado en datos que permite una gestión proactiva en lugar de soluciones reactivas. Las organizaciones que adopten estos paradigmas modernos de monitoreo mantendrán ventajas competitivas gracias a una mayor confiabilidad del servicio, respuestas más rápidas a incidentes y una toma de decisiones estratégicas mejor informada.
Aquellas que continúen operando con enfoques de monitoreo obsoletos enfrentarán costos operativos crecientes, vulnerabilidades de seguridad y desventajas competitivas que se acumulan con el tiempo.
Mientras diseñamos la próxima generación de infraestructura de internet, el monitoreo integral de DNS debe reconocerse no como un gasto operativo sino como una inversión estratégica en resiliencia empresarial y posicionamiento competitivo. Hoy existen las herramientas y marcos para implementar capacidades de monitoreo de DNS de clase mundial; la pregunta es si las organizaciones actuarán de manera proactiva o esperarán hasta que el próximo fallo catastrófico las obligue a hacerlo.
SOLUCIONES GLOBALES DE DIRECCIONES IP
Servicios profesionales de intermediación para transferencias seguras de IP, bloques de direcciones con buena reputación y soporte LIR en todos los registros regionales.

Alexei Krylov
Head of Sales
InterLIR GmbH es un marketplace de rápido crecimiento enfocado en abordar los problemas
La utilización eficiente del espacio de direcciones IPv4 existente es un enfoque
Incluso si no planeas vender tu bloque IPv4, aún hay formas de obtener ganancias
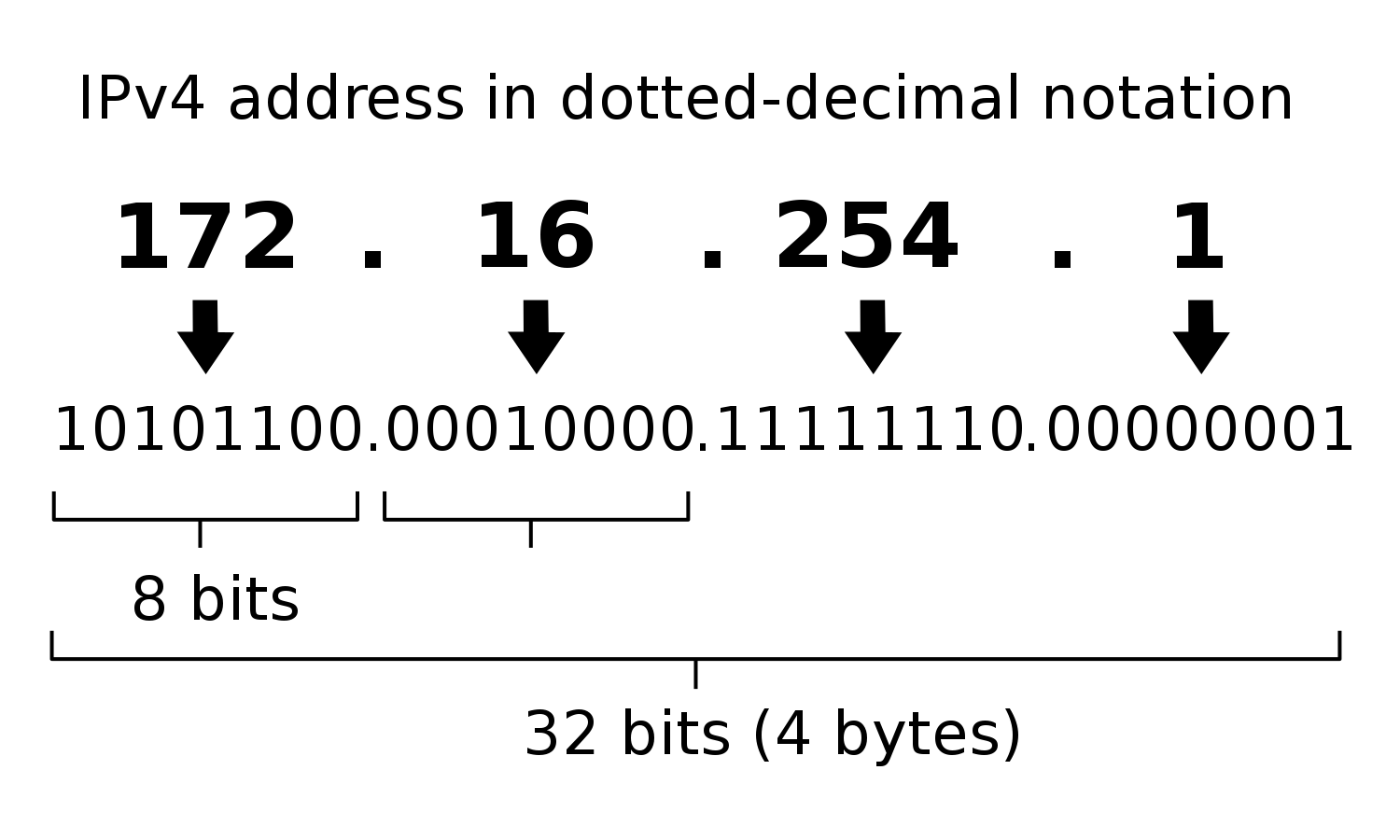
Una dirección de Protocolo de Internet (IP) es un identificador único asignado
La creciente demanda de bloques de direcciones IP ha elevado los precios y ha convertido
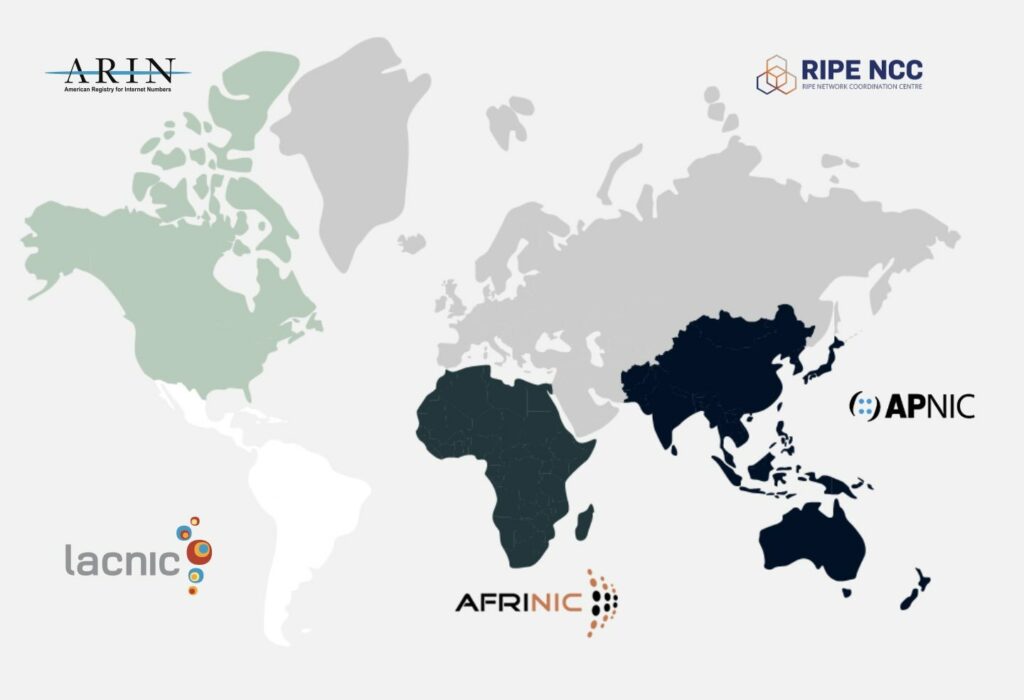
Todo lo que necesitas saber sobre la política de transferencia, fusión, adquisición
Esta política permite transferir direcciones IP solo dentro de la región. Además,
La política de transferencia inter-RIR permite la utilización eficiente del espacio
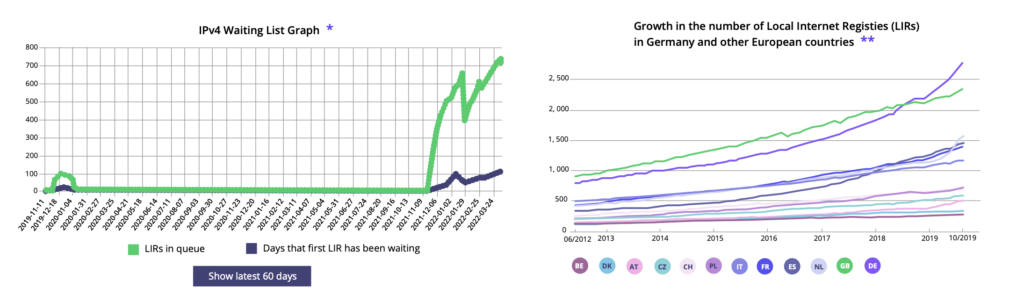
La agotación de direcciones IPv4 es un problema urgente, y las empresas se están